
基于FPGA的规则(3,6)LDPC码译码器
2008-07-29
作者:李智明 王 琳 范 雷
摘 要: 基于软判决译码规则,采用完全并行的解码结构,使用Verilog硬件描述语言,在Xilinx公司的FPGA(Virtex-2 xcv1000)上实现了码率为1/2、帧长为20bit的规则(3,6)LDPC码的译码器" title="译码器">译码器,最大" title="最大">最大传输速率" title="传输速率">传输速率可达20Mbps。对LDPC码的实际应用具有重要的推动作用。
关键词: LDPC码 变量节点 校验检点 因子图 译码
在通信系统中纠错码" title="纠错码">纠错码被用来提高信道传输的可靠性和功率利用率,低密度奇偶校验码(LDPC码)是目前最逼近香农限的一类纠错码。1962年,Gallager[1]首次提出了LDPC码的古典模型,即规则(regular)的LDPC码:(n,j,k),校验矩阵H具有恒定的列重量和行重量。LDPC码由于比Turbo码更接近香农限的误码率性能[2]和完全并行的迭代译码算法使其比Turbo码在部分场合具有更广泛的应用前景,从而使LDPC码成为当前纠错编码的一个研究热点。基于良好的译码性能,LDPC码被认为是通信系统的下一代纠错码。
1 规则LDPC码
1.1 因子图描述
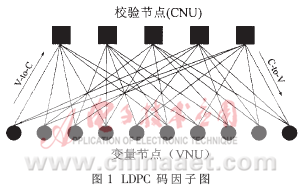
因子图[2]有两类顶点,分别为变量节点(variable nodes,用空的圆点表示)和校验节点(check nodes,用方框表示)。Tanner图就是这两类顶点之间的二部图,即每条边的一端与变量节点相连,另一端与校验节点相连。变量节点代表实际的变量,校验节点代表这些变量节点之间的约束。对于(j,k)-LDPC码的每个变量(bit)都受j个校验(check)的约束,因此每个变量节点应该连接j个校验节点。每个校验方程有k个变量,因此每个校验节点应与k个变量节点相连。由于LDPC是一种线性码,使得它的因子图一边为变量节点,一边为校验节点,故LDPC码的因子图表示有专用的定义:二部图(bipartite graphs)。
图1表示了校验矩阵为H的规则(3,6)LDPC码的因子图,它是由10个变量定点和5个校验定点组成的二部图,边刚好对应于矩阵中1的位置,这种因子图是LDPC迭代译码算法的基础。
1.2 LDPC码的译码算法
LDPC码的译码采用信度传播(belief-propagation或BP)算法[1],它与因子图相对应,如图1所示,利用BP算法获得好的译码性能,LDPC码的因子图中环的长度必须尽可能地长,长度为4的环会降低BP算法的性能,H矩阵设计时应避免出现。如果直接使用BP算法,由于在迭代过程中存在大量的乘运算,将使硬件的复杂度大幅度上升,本论文采用改进的Log-BP算法[1][4],把大量的乘运算转换成加运算,从而降低硬件复杂度及生产成本。
首先定义可能用到的几个变量及符号的意义:H表示一个M×N的LDPC校验矩阵,Hi,j表示矩阵H中第i行第j列的元素。定义校验节点m上的第n个变量节点为N(m)={n:Hm,n=1},关联在变量节点n上的第m个校验节点为M(n)={m:Hmn=1}。定义校验节点m上关联的除了第n个变量节点以外的所有变量节点为N(M)n,变量节点n上关联的除了第m个校验节点外的所有校验节点为M(n)m。
Log-BP算法的译码过程:
输入数据:初始概率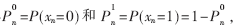 n=1, …, N;
n=1, …, N;
输出数据" title="输出数据">输出数据:硬判决结果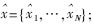
译码过程:
初始化:对于接收到的每个变量节点n计算初始信道信息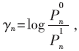 并对每个点计算初始信息,其中(m,n)∈{(i,j)|Hi j=1}。
并对每个点计算初始信息,其中(m,n)∈{(i,j)|Hi j=1}。

迭代译码:
(1)校验节点计算
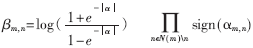

对于每个变量节点n,在完成变量节点计算后,对
(3)判决条件
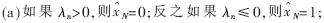
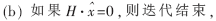 否则跳到第2步迭代译码部分,直至校验成功或者达到最大迭代次数。
否则跳到第2步迭代译码部分,直至校验成功或者达到最大迭代次数。
上面算法中的αm,n和βm,n都被称为外部信息,其中αm,n是从变量节点向校验节点传递的信息,βm,n是从变量节点向校验节点传递的信息。通过log-BP算法和BP算法的比较可以发现,log-BP算法中除了f(x)=log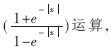 剩下的都是加法运算,从而避免了BP算法中乘运算过多的弊病。在本文中函数f(x)利用FPGA中的查找表(Look-up Table, LUT)实现。
剩下的都是加法运算,从而避免了BP算法中乘运算过多的弊病。在本文中函数f(x)利用FPGA中的查找表(Look-up Table, LUT)实现。
2 H矩阵的生成
Gallager提出的LDPC码的H矩阵[1]必须满足以下两点:
(1)H矩阵的每一列有j个1,j>=3;
(2)H矩阵的每一行有k个1,k>j;
本文中选择j=3,k=6,通过编程用matalab软件生成若干满足条件的H矩阵,选择其中一个性能最好的H矩阵进行LDPC码的fpga译码实现。当n=20时,最终选择H矩阵如图2所示。

3 LDPC码完全平行译码结构
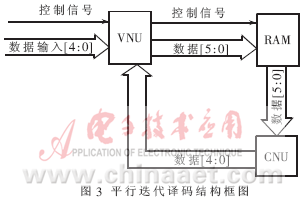
由二部图可以直观地看出,变量节点计算需要的信息只需由校验节点来提供,校验节点计算需要的信息只需要由变量节点来提供,译码器在设计时可以给每个变量节点分配一个变量节点处理单元(Variable Node processing Unit,VNU),给每个校验节点分配一个校验节点处理单元(Check Node processing Unit,CNU),从而实现译码器的完全并行结构。
译码器的核心模块是迭代译码部分,迭代译码的结构与算法是紧密相连的,译码结构的确定必须在仔细分析算法的基础上,迭代译码的过程是CNU和VNU模块计算结果的相互传递和更新。如果直接将CNU和VNU连接,不但不容易控制迭代的过程并且可能出现不稳定状态,所以需要在CNU和VNU之间安插RAM以起到数据的缓冲和控制作用。输入、输出模块分别控制数据的输入和输出,当条件满足或者是迭代完成时,读入数据并把迭代结果输出。
3.1 迭代译码结构
图3表示平行迭代译码结构[5][6]。其中只画出两个节点之间一条数据通路的连接方式,因为是完全平行迭代译码结构,其他节点之间数据通路的连接方式与此相同。信道初始化数据送入VNU模块进行数据处理后,送入RAM模块,数据经过CNU模块,最后再送入VNU模块,这样就完成一次迭代。数据信息从VNU到CNU与数据信息从CNU到VNU分别在不同的数据线上传输(图1)。
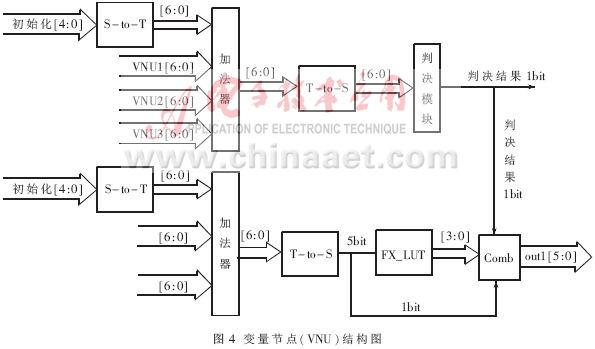
3.2 变量节点结构(VNU)
变量节点的结构如图4所示。从中可以看出每个变量节点的度为3(j=3),四个5 bit输入信息包含一个信道信息和三个与之相连的校验节点的信息。由log-BP算法可以看到α进行的是量化值的计算,没有牵扯到符号位,而γm,n和λn的计算都有包含符号位的相加,实际上其中还包含了减法运算,而本文采用的符号信息位的格式不能用于减法运算,需要将其转换为其他格式。在本文进行和运算时,首先将其转换为二进制补码形式,运算结束后再转换回符号量化位格式,查表(FX_LUT)进行f(x)运算。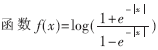 可由FPGA中的逻辑单元LUT来实现。Comb模块把1bit的判决结果x、4bit的查找表运算结果与符号位合在一起作为外部信息送入校验节点(CNU)。图4上半部分为输出译码的结果,下半部分为三个数据输出通道中的一个,其余两个的结构与此完全相同,唯一不同的是加法器的输入, 根据log-BP算法,其中初始化数据经过S-to-T转换后的数据输入固定,另外两个输入数据为其他两个数据通道的输入经过S-to-T转换后的数据。
可由FPGA中的逻辑单元LUT来实现。Comb模块把1bit的判决结果x、4bit的查找表运算结果与符号位合在一起作为外部信息送入校验节点(CNU)。图4上半部分为输出译码的结果,下半部分为三个数据输出通道中的一个,其余两个的结构与此完全相同,唯一不同的是加法器的输入, 根据log-BP算法,其中初始化数据经过S-to-T转换后的数据输入固定,另外两个输入数据为其他两个数据通道的输入经过S-to-T转换后的数据。
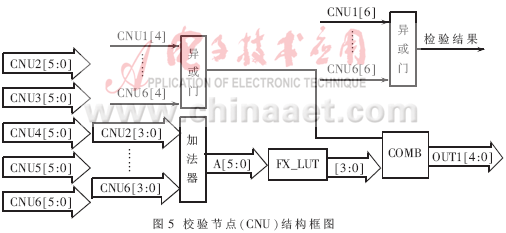
3.3 校验节点结构(CNU)
校验节点(CNU)结构如图5所示,每个检验节点的度数为6(k=6),图5只画出数据的一个输出通道,其余5个输出通道的结构与此完全相同,加法器为检验节点首先对外部信息中的判决结果进行验证,看是否满足H·xT=0,满足则结束迭代。CNU模块中f(x)的x计算是只计算量化值而不管正负的,而本译码器采用的符号量化位格式只需将符号位屏蔽即可得到相当于绝对值效果的量化位运算,也就是CNU模块中不需要将符号量化位转化为二进制补码形式。
3.4 数据输入与输出
完全平行译码结构可以分为三部分:迭代译码模块、数据输入模块和数据输出模块。因为是完全平行译码方式,输入数据经过串并转换后,同时读入VNU进行迭代计算。在数据输出模块,每一次迭代完成要进行条件判别,如果CNU所有的校验结果都为零,则输出数据。或者已经完成17次迭代,此时强制输出数据。数据的输入与输出分别用不同的时钟进行控制。图6为译码器其中一帧数据的测试结果,编码之前的信息为01010101,图6中OutData为编码后数据的输出。

4 FPGA实现
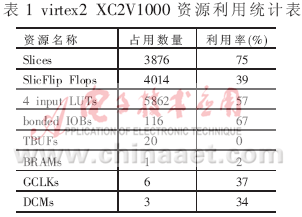
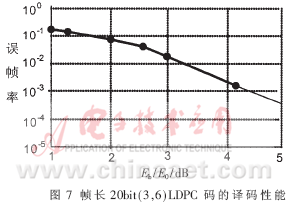
根据规则(3,6)LDPC码的完全平行译码结构,选择在Xilinx Virtex2 XC2V1000-fg256上对其进行物理实现,译码器采用Verilog硬件描述语言编写,用Xilinx的开发工具ISE6.1在XC2V1000上对译码器进行布局布线。硬件资源的占有率如表1所示。通过时序分析可以看出,译码器的最大时钟频率为20MHz,以输入时钟为基准,完成17次迭代最多需要20个时钟,完成一帧数据的输入需要20个时钟,可以得出译码器的最大译码速率为:V=20×20/20=20Mbps。图7为帧长为20bit的LDPC码的译码性能,因为码长较短,性能没有达到最好。这为更高速 LDPC码译码器的设计打下坚实的基础,码长为1024bit,传输速率可进一步提高,甚至达到1Gbps,译码性能会更好[6][7]。
本文基于软判决译码规则,采用完全平行译码结构,设计出帧长为20bit,码率为1/2的规则(3,6)LDPC码的译码器,在Xilinx virtex2 XC2V1000-fg256上对其进行物理实现,最大迭代次数为17次,传输速率达到20Mbps。LDPC码具有良好译码性能,与Turbo码相比更易于硬件实现,并能得到更高的译码速度。下一步将设计出码长为1024bit或码长更长的LDPC译码器,进一步提高传输速率,降低误码率,为加速该技术在中国的商用奠定基础。
参考文献
1 R.G. Gallager.Low density parity check codes.IRE Trans. Inform. Theory,1962; IT-8(Jan):21~28
2 R. M. Tanner. A recursive approach to low complexity codes.IEEE Trans. Inform. Theory,1981; IT-42:533~547
3 M. Chiani, A. Conti, and A. Ventura.Evaluation of lowdensity parity-check codes over block fading channels. in 2000 IEEE International Conference on Communications. 2000:1183~1187
4 S. Kim, G. E. Sobelman, J. Moon.Parallel VLSI Architectures for a Class of LDPC Codes. Circuits and Systems.IEEE International Symposium on, 2002;Volume:2
5 C. J. Howland and A. J. Blanksby.Parallel decoding architectures for lowdensity parity check codes. in Proc. IEEE ISCAS,2001;4(5):742~745
6 A. J. Blanksby and C. J. Howland. A 690-mW 1-Gb/s 1024-b, rate-1/2 low-density parity-check code decoder. IEEE Journal of Solid-State Circuits,2002;37(3):404~412
7 T. Zhang and K.K. Parhi.VLSI implementation-oriented(3,k)egular low-density parity-check codes. IEEE Workshop on Signal Processing Systems (SiPS), 2001;9