
当前,数字信号处理器(DSP)芯片以其强大的运算能力在通信、电子、图像处理等各个领域得到了广泛的应用。使用DSP的系统可以按处理器使用的数目分为单处理器系统和多处理器系统。单DSP的系统尽管结构简单,但系统的功能将不可避免地有所限制。由于DSP的控制功能不是非常强大,在应用中往往不得不把DSP作为目标系统专门负责复杂的运算,而另外使用一个主机(PC机或是单片机)对整个系统的运行实行控制。所以,在使用DSP的多处理器系统中,主机(单片机、PC机、另一个DSP芯片)与目标系统 DSP的数据交换就成为应用系统设计中必须考虑的重要问题。
1 主机接口的传统解决方案
解决主机与目标系统的数据交换是一个非常复杂的问题。传统的方式是采用 DMA(Direct Memory Access)或全局存储器(Global Memory)完成多机系统中的数据共享。在DMA方式下,读写共享内存必须要求其它处理器处于停止工作的状态,所以DMA共享存储器的方式往往不为人所用。全局存储器是多个处理器共享的存储器。在使用全局存储器的应用系统中,DSP的地址空间被分成局部块(Local Section)和全局块(Global Section)。局部块用于完成处理器自己的工作,而全局块则用来完成与其它处理器的通信工作。在TMS320C5X器件中,使用全局存储器分配寄存器GReg完成对全局内存的管理工作。GReg指定部分DSP内存为全局内存。比如,TMS320C5x器件能够分配全局数据内存空间,并通过BR(Bus Request)和 hcs控制信号实现与该内存的通信。当需要寻址全局内存空间时,BR和hcs信号变低电平。于是外部逻辑进行全局内存控制权的裁决,裁决的结果将通过选通信号通知某个TMS320C5x 从而使该DSP现在就拥有对全局内存的控制权。显然,使用全局内存的方式来完成多DSP的共享数据通信是非常方便的。但是,应用系统往往由单片机作为主机,DSP作为目标系统构成。由于当前使用最多的单片机往往是8位机,使用16位机的共享内存完成主机与DSP的数据交换不是处理太复杂就是资源利用不充分。为了解决DSP与低档 8位主机的数据交换问题,TI公司在TMS320C54x系列中使用了HPI接口。HPI将以往一些需片外实现的功能集成在片内,简化了与主机的连接,同时主机可以达到很高的访问速度。该HPI端口在TI TMS320C6x系列的器件中也得到了保持,且功能有所增强。
TI TMS320C6x系列的器件中也得到了保持,且功能有所增强。
2 TMS320VC5402的HPI
TMS320VC5402是TI公司的54X系列定点DSP,具有低功耗、高性能的特点。
CPU 增强的多总线结构,三条独立的16bit数据存储器总线和一条程序存储器总线;40bit运算逻辑单元(ALU),包括一个40bit的桶形移位器和两个独立的40bit累加器,17bit×17bit并行乘法器连接一个40bit的专用加法器,可用来进行非流水单周期乘/加(MAC)运算;比较、选择和存储单元(CSSU)用于Viterbi运算器的加/比较选择指数编码器在一个周期里计算一个40bit累加器的指数值两个地址发生器中有八个辅助寄存器和两个辅助寄存器运算单元(ARAUs)数据总线具有总线保持特性。
存储器 扩展地址模式可最大寻址到1M×16bit外部程序空间,4K×16bit片上ROM,16K×16bit双访问片上RAM。
指令集 支持单指令循环和块循环,存储块移动指令提供了高效的程序和数据存储器管理,支持32bit长字操作数指令,支持两个或三个操作数读指令,支持并行存储和并行加载的算术指令、条件存储指令和中断快速返回,支持定点DSP C语言编译器。
片上硬件资源 软件可编程等待状态发生器和可编程存储单元转换,连接内部振荡器或外部时钟源的锁相环(PLL)时钟发生器,两个多通道缓冲串口(McBSPs),增强型8bit并行主机接口(HPI8),两个16bit定时器,6通道直接存储器访问(DMA)控制器。
电源 低功耗,工作电源有3.3V和1.8V(内核),用节电模式的IDLE1、IDLE2及IDLE3指令做功率控制,可禁止CLKOUT信号。
速度 在3.3V供电(1.8V核心电压)下单周期定点指令的执行周期为10ns(100MIPS)。
仿真 符合IEEE1149.1边界扫描逻辑标准的片内扫描仿真逻辑接口。
TMS320C54x系列DSP芯片中的HPI,能够顺序传送或随机传送数据,产生HOST中断和C54x中断,接口灵活,并可通过DMA总线访问片内RAM。当TMS320 C54X与主机(或主设备)交换信息时,HPI是主机的一个外围设备。HPI有8根数据线HD(0~7),在TMS320C54x与HOST传送数据时,HPI能自动将外部接口传来的连续数据组合成16位数后传送给DSP。如果HOST和DSP竞争同一个地址,则HOST优先,DSP等待一个HPI周期。
TMS320C54x系列发展到TMS320VC5402的时候,其HPI已经得到了增强,被称为HPI-8。和TMS320C54x系列前几款芯片中的标准HPI相比,HPI-8在几个方面有所不同,见表1。
表1 HPI-8和标准HPI的主要差别
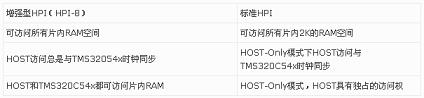
HPI-8的使用是通过对HPIA、HPIC和HPID三个寄存器赋值实现的。HPIA是地址寄存器,HPIC是控制寄存器,而HPID是数据寄存器。简单地说,HOST通过外部引脚HCNTL0和HCNTL1选中不同的寄存器,则当前发送的8位数据就送到该寄存器。在使用上,由于HPIC是16位寄存器,而HPI-8是8位的数据宽度,所以在HOST向HPIC写数据时,需要发送两个一样的8位数据。而地址寄存器HPIA选择后,直接向它写数据就可以了,但是要注意MSB和LSB的顺序。另外,HPIA具有自动增长的功能,在每写入一个数据前和每写入一个数据后,HPIA会自动加1。这样,如果使能了该功能,只需设定一次HPIA即可实现连续数据块的写入和读出。数据寄存器HPID,严格说应该叫做数据缓冲寄存器,因为最终数据是要写到片内RAM的。只是在实现上,数据首先从HOST发到HPID中,然后根据HPIA指定的地址,HPID中的数据再写到片内RAM的地址中。不过对用户而言,该过程是透明的。
3 使用HPI对DSP进行自举
HPI是作为多机数据交换而出现的,但是由于其功能特性,又产生了一种新的应用--使用HPI对DSP进行自举。实际上,TMS320VC5x系列DSP在片内固化的Bootloader程序中对HPI自举提供了全面的支持。笔者在VOIP系统的开发中,实现了使用HPI对DSP TMS320VC5402的自举,从而省掉了DSP的EPROM,使DSP只使用SRAM,提高了处理速度,并使HOST CPU具有更大的控制权,很适合多处理器系统。对于计算机插卡式的DSP系统,程序可以从PC机的硬盘上获取,从而减小了插卡版面空间占用,提高了处理速度。
在实现上,需要解决以下几个问题。
3.1 DSP片内固化的Bootloader程序对HPI自举的支持
自举从本质上说就是在DSP启动后通过某种方式获取运行代码并开始运行,这个过程是在固化在DSP片内的Bootloader程序辅助下完成的。在DSP上电以后,Bootloader程序按照一定的顺序依次检验何种自举方式可用,自举方式包括HPI方式、Serial EEPROM方式、标准Serial Port方式、Parallel方式和I/O方式。
Bootloader查询HPI方式是否可用是这样进行的:在启动以后,DSP片内0x7f地址的值被置为0,Bootloader不断检验0x7f地址处是否出现了可用的程序指针的跳转地址。当其发现该地址内的值不为0时,即判定为DSP已由外部HOST CPU进行了HPI自举程序加载,并按照该值跳转PC指针,开始运行,从而完成HPI方式自举。
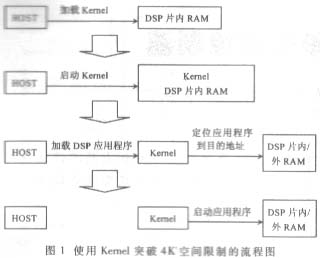
3.2 突破4K的空间限制
由于HPI-8的特性,HOST能够访问所有的片内RAM空间,对于TMS320VC5402来说,其片内RAM地址空间从0000H到3fffH,一共4K。这已经大大超过了标准HPI的2K的大小,但是对于大多数DSP应用程序来说,片内RAM除了放置程序代码以外,很可能还需要留出一部分供数据空间使用。实际上,大部分代码都可能放置在片外的程序空间,而这部分空间并不是HOST通过HPI-8所能够访问得到的。所以需要使用某种技术突破4K的片内RAM空间限制。由于DSP程序本身是能够访问到所有DSP程序、数据空间的,所以HOST可以首先放置一个体积不大于4K的程序到DSP内,再由该程序和HOST协作完成超出片内RAM的代码的放置工作。
一般将上述的首先放入DSP的程序称为Kernel程序,其功能比较简单,本身不超过4K,可以由HOST全部放入到TMS320VC5402的片内RAM中,并被启动。
基于此种思路的流程图如图1所示。
3.3 程序代码的定位
编程序的时侯使用符号作为地址,经编译、链接后,符号所表示的相对地址已经转化为绝对地址。要使程序能够正常运行,需要将程序代码写到指定的位置--绝对地址。在 HOST→Kernel→DSP应用的HPI自举方式中,HOST和Kernel需先后完成Kernel代码和DSP应用程序代码的定位工作。
因此,在HOST CPU的外存储器中,至少需要保存DSP程序代码和相应的地址信息。这些数据在由自举程序写到DSP后,被拼接成正确的可执行代码、已初始化数据等,并被正确定位。一般来说,HOST CPU的外存储器中的DSP自举数据是HEX格式的。虽然HEX格式有很多种,但任何一种包含有地址等信息的16进制HEX格式文件都是适用的。
常见的HEX格式有ASCII、Intel、TI-Tagged等格式,如图2所示。
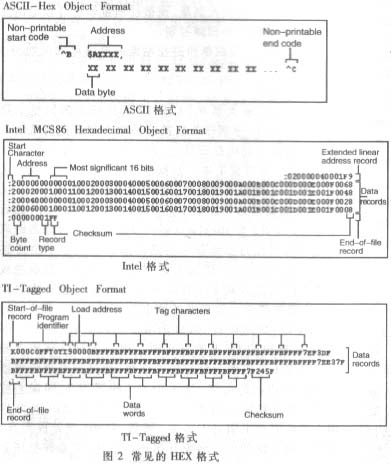
在各种HEX格式中,Intel格式相对来说比较适宜,因为在Intel格式的HEX文件中,代码被分为每行一个块,这种分块的最大长度固定,因此在DSP内预留的缓冲区的大小容易计算。Intel格式的HEX文件的格式为:BYTE1作为每块的起始标志,总是":";BYTE2-3表示该块中有效数据的长度,最长为32个BYTE。这种有效数据可能是程序代码,也可能是扩展地址信息;BYTE4-7表示该块内代码的起始地址;BYTE8-9是类型,00表示程序代码,01表示结束,04表示扩展地址信息;BYTE10之后是代码,直到最后两个BYTE,表示校验位。校验位的值是该块中先前数据值和的补码。
根据选定的HEX格式,CPU首先按照该格式的定义对Kernel的HEX数据进行解释,获取各种信息后,CPU将其在TMS320VC5402片内RAM中组成可执行DSP程序。然后在CPU和kernel的共同作用下,对DSP应用程序的HEX数据进行解释,最后完成其在DSP中的拼接、定位并启动DSP应用程序--跳转到DSP应用程序的起始地址。
4 系统软硬件设计与实现
4.1 系统框图
在笔者开发的VOIP系统中,使用了HPI对DSP (TMS320VC5402)进行自举的功能。其中相应部分的框图如图3所示。
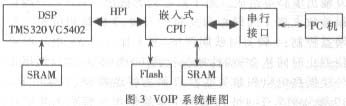
对于PC机插卡的系统,该框图更可以省略掉HPI以右的部分,而直接使用PC机的CPU和硬盘作为相应的控制和只读存储器件。这样,仅需要为DSP配备RAM即可使其正常运行。
4.2 Kernel程序设计
按照前面所说,kernel程序的作用是用于突破TMS320VC5402 4K片内RAM空间限制的中间程序,其功能无非就是按照和HOST CPU的某种约定,获取DSP程序代码和相应地址信息,在DSP所能够访问到的存储器空间(片内和片外)生成DSP程序代码。由于 Kernel的功能比较少,故其可以做得非常小。其中关键的生成DSP程序代码部分的代码如下:

4.3 运行流程
按照前述的系统构成,首先将PC机上调试好的Kernel程序和DSP应用程序(一般为COFF格式)转换成HEX文件,并通过串口将这些文件存放到CPU的Flash中,在存放过程中应将HEX文件原样保存,以保留其中所有的信息。在系统启动后,CPU从Flash中获取Kernel的HEX数据,通过HPI将其在TMS320VC5402中组合出Kernel运行程序并启动。然后,CPU从其Flash中获取DSP应用程序的HEX数据,通过HPI将其分块放入TMS320VC5402,并和已经开始运行的Kernel程序最终完成DSP引用程序的正确定位工作。最后启动DSP应用程序。
在实践中发现,虽然HPI的设计初衷是为了和低速8位机接口进行数据交换,但是HPI本身的工作速度非常高。通过HPI方式加载一段不小于130K的DSP应用程序代码所需要的时间不超过3秒钟。
TI系列DSP提供了如此丰富的应用方式,无疑给DSP系统开发者带来了极大的方便。