
基于GA和神经网络的非线性特征变换
2008-09-01
作者:齐春亮, 马义德
摘 要: 在分析传统方法的基础上,将GA与神经网络相结合,提出了一种特征变换" title="特征变换">特征变换的新方法,二者优势互补,通过与传统的特征选择方法比较,用实例验证了该方法的正确性和可信性。
关键词: GA 神经网络 特征选择 特征变换
在机器学习和KDD领域,事物的属性和属性取值反映了事物的本质和度量,为了描述一致,统称为模式特征。在传统文献中,模式特征一般分为物理特征、结构特征和数学特征[1~2]。物理特征和结构特征容易被人类感官所接受,便于直接识别对象。在人工智能领域,物理特征和结构特征以数学特征的形式表现出来,特征提取" title="特征提取">特征提取主要指特征数据的处理方法和过程。广义上的特征提取按属性数据的处理方式分为特征直接提取和间接提取,又称为特征选择和特征变换。
(1)直接提取(特征选择):设原始特征集合为Un={A1,A2,…,An},直接提取即从Un中挑选出有利于分类的特征子集: ![]()
其中,d<n,Ud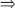 Un,特征空间的维数得到了压缩。
Un,特征空间的维数得到了压缩。
(2)间接提取(特征变换):通过映射或变换的方法,把高维空间Un的高维特征转化为低维空间Ud的低维特征: Te:Und
其中,d≤n,在特征空间变换过程中,特征维数得到了压缩,但是压缩的前提是保证样本的分类性质保持不变。Te可以采用线性或者非线性变换模型。
特征选择的主要算法包括枚举法、分支定界搜索法、逐个特征比较法等启发式方法[3]。在实际运算时,启发式算法" title="启发式算法">启发式算法无论采用深度优先或者广度优先,过程控制都非常复杂,且对噪音的处理非常不方便。从本质上讲,任何启发式算法都是一种局部寻优方法,所获得的解通常不是最优解,同时难于发现多个最优解或满意解[4~5]。另外,启发式算法的求解结果对噪音比较敏感,影响了特征子集的鲁棒性和适应性。
在概念学习或者更为广泛的模式识别领域,特征提取是一个非常复杂的问题,所表示的模型求解基本上是NP类问题[6~7],一般需要综合考虑分类错误、特征简单性和计算时间资源等因素。
传统的特征提取方法通常采用线性变换,使得判别准则函数最大或者最小(熵函数和类内类间距离函数是经常采用的两个准则函数,[1]),即
Y=A*X
其中,A*为d×n维的变换矩阵,将n维特征的原始样本空间X变换为d维特征的样本空间。这就是传统特征提取的统计与代数方法。在这两种方法中存在着强烈的统计假设和矩阵非奇异假设,而在实际环境中,这些要求很难得到满足。对于大规模的实际问题,通常采用专家干预的方法进行调整,使得计算过程变得非常繁琐,导致这两类方法的实用性受到很大的限制。尤其是面对非线性可分的样本空间时,传统的统计与代数方法显得更加无能为力,难以实现分类模式的获取。因此许多专家提出了各种各样的非线性特征提取方法,例如基于K-L展开式的KLT方法[1]、神经网络方法[8]、小波分析[9]等。KLT是最小均方误差准则下的最佳K-L变换方法,不受样本分布性质的限制,但是不存在快速算法,计算量是维数的指数函数,当维数比较高时,计算量难以承受。在实际中经常采用傅立叶变换(DFT)或者离散沃尔什变换(DWT)等代替。这些变换均存在相应的快速算法,但仅能得到次优的结果。小波分析与KLT方法具有相同的特点,也存在类似的问题。
模式分类是神经网络的一个重要应用领域,在输入存在或数据不完整的情况下,神经网络也具有良好的分类能力[10~12],特别是三层以上结构的多层感知器系统的神经网络模型" title="网络模型">网络模型可以灵活地处理非线性可分问题。但是神经网络模型的求解算法不仅效率低,而且容易陷入局部极值点。基于此,本文将神经网络的表示能力与GA的全局求解能力结合,用于非线性特征提取问题。
1 基于GA和神经网络的非线性特征变换算法
1.1 神经网络结构设置
根据神经网络理论,三层感知器可以形成任意复杂的决策区域[8,11],对于特征提取来讲,将第三层作为特征输出层,并要求输出二进制类型数据作为特征数据。网络模型为:隐层节点的激励函数选择连续型Sigmoid函数f(x)=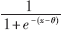 ,输出层节点的激励函数选择f(yk)=sgn(
,输出层节点的激励函数选择f(yk)=sgn( ),(k=1,2…,d),输出{-1,1},向量转化为{0,1}作为新的特征向量。
),(k=1,2…,d),输出{-1,1},向量转化为{0,1}作为新的特征向量。
1.2 GA方案安排
把GA应用于实际问题时,首先需要解决编码和适应度函数的设计,然后是三个进化算子(选择、交叉和变异算子)的设计,当然还有初始条件和收敛条件的设置,运行GA以求得问题的准最优解。本文的遗传算法" title="遗传算法">遗传算法应用方案设计主要为以下步骤:
(1)编码
在遗传算法理论中有两种主要的编码方式:二进制编码和实数编码。二进制编码进化的层次是基因,浮点数进化的层次是个体。大量的实验结果表明:对同一优化问题二进制编码和实数编码GA不存在明显的性能差异。本文采用二进制编码。
基于二进制的染色体位串由五部分组成:隐层节点数s1:a1a2…a(2n+1);输入节点到隐层节点的连接权重编码s2:b11b12…b1nb21b22…b2n…b(2n+1)|b(2n+1)2…b(2n+1)n;隐层节点到输出节点的连接权重编码s3:c11c12…c1(2n+1)c21c22…c2(2n+1)…cd1cd2…cd(2n+1);隐层节点激励函数的阈值编码s4:d1d2…d(2n+1);输出函数的阈值编码s5:e1e2…ed。
将上述五个部分连接在一起就构成了整个模型的编码。其中连接权重和阈值编码限定范围是[-1,1]。
(2)适应值函数
遗传算法在搜索进化过程中一般不需要其他的外部信息,仅用适应度来评价个体的优劣,并以此作为遗传操作的依据。设计一个好的适应度函数对于遗传算法的执行效率和结果有着至关重要的影响,本文以熵函数(见式(1))为基础,并考虑网络结构的简单性,构造出本算法的适应值函数(式(2))。
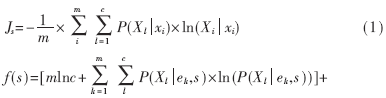

其中α、β为熵函数值与神经网络结构之间的平衡系数,第二项要求网络中隐层节点数越少越好,第三项要求网络中连接数越少越好,以提高网络的稳定性。
(3) 选择
采用适应度比例方法,并保留每一代的最佳个体。
(4) 交叉
交叉互换能产生不同于母体的后代,交叉的概率越高,群体中新结构引入越快;如果交叉概率太低,收敛速度可能降低,导致搜索阻滞。在此,采用双点交叉,交叉概率设置为0.6。
(5) 变异
变异操作是保持群体多样性的有效手段。变异概率太小,可能是某些基因位过早丢失的信息无法恢复;变异概率过高,遗传搜索将变成随机搜索。在此,采用基本变异算子,变异概率设置为0.001。
(6) 种群规模
若种群规模过大,则适应度评估次数增加,计算量增大;种群规模过小,可能会引起未成熟收敛现象。因此种群规模的设置应该合理。在此,种群规模取为6000,最大繁殖代数(进化代数)设置为500。
(7) 终止准则
任何算法设计的最后一步都要分析其收敛条件。在本文中算法执行满足下列条件之一时,算法终止:
·最大的适应度值在连续四代之内变化小于0.001,算法终止。
·上述条件不满足时,算法执行到最大进化代数时自动终止。
保证算法收敛的策略:采用杰出人才保持模型,即用每一代内的最优个体替代下一代内的最差个体,从而使得算法完全收敛。
1.3 算法描述
网络参数设置:输入节点数n1=22,隐层节点数n2=45,输出节点数d=13,输入节点到隐层节点的连接数900,隐层节点到输出节点的连接数580。
GA参数设置:位串长度L=12705,群体规模n=6000,交叉概率pc=0.6,变异概率pm=0.001,进化代数为500,每个实数参数的二进制编码长度设为8。
算法主要流程:
(1) 初始化:设置群体规模N=6000,进化代数G=500,交叉概率Pc=0.6和变异概率Pm=0.001,染色体长度chromlength=12705,随机产生初始种群;
(2) 令G=1,进入循环;
(3) 对30个个体进行解码,代入神经网络模型,根据适应值函数(见式(2))计算个体的适应度;
(4) 进行遗传操作:精英选择、双点交叉、基本变异;
(5) G=G+1,判断是否满足终止准则;
(6) 不满足,转到第(3)步;满足,进化(循环)终止,输出最佳个体。
2 应用实例
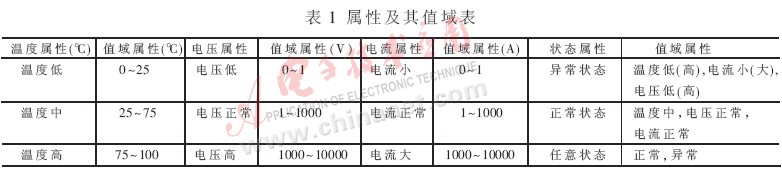
将上述方法应用到一水轮发电机的仿真机上进行实践。对原始数据表中的属性进行特征抽取和变换,原始数据表(含12个属性和3000行对应的属性值)数据量很大, 由于篇幅有限不予列出[13], 属性及其值域的表格如表1所示。
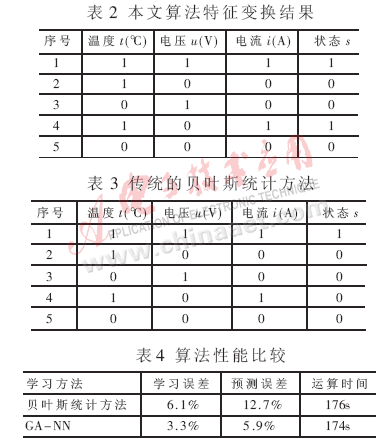
采用文中提出的方法提取的特征结果形式如表2所示,其中提取的特征属性为温度t、电流i和电压u,对应的属性值为概括后的特征值(假设t表示发电机的线圈温度,i表示其定子电流,u表示定子电压,s表示其工作状态),t、i、u对应的1表示正常,0表示异常;s对应的1表示正常状态;2可表示异常状态。为了测试本文算法,将其与传统的贝叶斯方法进行比较,如表3、表4所示。
从上表实验数据可以看出,经过GA与神经网络的结合,二者的优越性都得以发挥,学习误差和预测误差都有所下降,且运行时间减少;分类精度要高于传统的贝叶斯统计方法20%左右,且学习误差和预测误差降低了将近50%。通过对比,可以看出GA-NN相结合进行的特征变换达到一般特征提取的精度要求,在相同的评价体系下,本文提出的算法是有效且可信的。
神经网络用于特征提取是一个规模非常庞大的优化问题,系统结构中含有大量的冗余节点和连接,获得可行解的速度比较快,但是寻找最优解需要长时间的进化和训练。为此采用了神经网络与遗传算法相结合的混合算法进行特征提取,通过实验验证,效果较好。但是存在的不足是随着特征数量和实例样本量的增加,神经网络的GA求解的计算量将成指数增加,需要采用大型计算机或超级并行计算机。这对于其推广应用是一个严峻的挑战。
参考文献
1 傅京孙. 模式识别及其应用. 北京:科学出版社,1983
2 沈 清,汤 霖.模式识别导论.长沙:国防科技出版社,1991
3 李金宗.模式识别导论.北京:高等教育出版社,1996:127
4 陈 彬,洪家荣,王亚东.最优特征子集选择问题.计算机学报,1997;20(2):133~138
5 钱国良,舒文豪,陈 彬.基于信息熵的特征子集选择启发式算法的研究.软件学,1998;9(12):911~916
6 Michalski,R.S., Teluci,G.Machine learning:a multi-strategy approach. San Francicso. CA:Morgan Kaufmann,1994;4
7 Jia rong. H.Inductive learning:algorithm,theory,application.Beijing: Science Publishing House of China,1997
8 钟义信,潘新安,杨义先.智能理论与技术-人工智能与神经网络.北京:人民邮电出版社,1992
9 Fionn Murtagh,Wedding the wavelet transformation and multivariate data analysis Journal of Classification,1998;(15):161~183
10 Brill,F.Z. Fast genetic selection of feature for neural network classififier.IEEE Transactions on Neural Networks,1992;3(2):324~328
11 Ripley,B.Pattern recognition and neural networks.New York:Cambridge Press,1996
12 Rudy Setiono,and Huan Liu.Neural Networks feature selector.Department of Information systems and Computer Science.National University of Singapore,1996
13 Zhang D G,Zhao H.Fuzzy-neural theory applied to electric fault fusion in monitoring system of hydropower plant[A].The 4th Information Fusion International Conference [C].Montreal:CM Press,2001.10