
所谓探索性数据分析(EDA" title="EDA">EDA),是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是当我们对这些数据中的信息没有足够的经验,不知道该用何种传统统计方法进行分析时,探索性数据分析就会非常有效。探索性数据分析在上世纪六十年代被提出,其方法由美国著名统计学家约翰·图基(John Tukey)命名。
EDA的出现主要是在对数据进行初步分析时,往往还无法进行常规的统计分析。这时候,如果分析者先对数据进行探索性分析,辨析数据的模式与特点,并把它们有序地发掘出来,就能够灵活地选择和调整合适的分析模型,并揭示数据相对于常见模型的种种偏离。在此基础上再采用以显著性检验和置信区间估计为主的统计分析技术,就可以科学地评估所观察到的模式或效应的具体情况。
所以概括起来说,分析数据可以分为探索和验证两个阶段。探索阶段强调灵活探求线索和证据,发现数据中隐藏的有价值的信息,而验证阶段则着重评估这些证据,相对精确地研究一些具体情况。在验证阶段,常用的主要方法是传统的统计学方法,在探索阶段,主要的方法就是EDA,下面我们重点对EDA做进一步的说明。
EDA的特点有三个:一是在分析思路上让数据说话,不强调对数据的整理。传统统计方法通常是先假定一个模型,例如数据服从某个分布(特别常见的是正态分布),然后使用适合此模型的方法进行拟合、分析及预测。但实际上,多数数据(尤其是实验数据)并不能保证满足假定的理论分布。因此,传统方法的统计结果常常并不令人满意,使用上受到很大的局限。EDA则可以从原始数据出发,深入探索数据的内在规律,而不是从某种假定出发,套用理论结论,拘泥于模型的假设。
二是EDA分析方法灵活,而不是拘泥于传统的统计方法。传统的统计方法以概率论为基础,使用有严格理论依据的假设检验、置信区间等处理工具。EDA处理数据的方式则灵活多样,分析方法的选择完全从数据出发,灵活对待,灵活处理,什么方法可以达到探索和发现的目的就使用什么方法。这里特别强调的是EDA更看重的是方法的稳健性、耐抗性,而不刻意追求概率意义上的精确性。
三是EDA分析工具简单直观,更易于普及。传统的统计方法都比较抽象和深奥,一般人难于掌握,EDA则更强调直观及数据可视化,更强调方法的多样性及灵活性,使分析者能一目了然地看出数据中隐含的有价值的信息,显示出其遵循的普遍规律及与众不同的突出特点,促进发现规律,得到启迪,满足分析者的多方面要求,这也是EDA对于数据分析的的主要贡献。
值得一提的是,正因为EDA更强调直观及图形显示,所以它采用了很多创新的可视化技术,目前这些可视化技术已经有了很好的实现载体,目前最为主流的探索性数据分析软件是以图形效果好、交互性强、易学易用著称的统计发现软件JMP" title="JMP">JMP。即使不具备统计学基础的分析者也能在JMP的帮助下,轻松地发现数据、拟合以及残差的规律,获得意想不到的发现,为后续的分析启发思路、指明方向。
下面,用一个典型的小案例来说明EDA的实际应用。
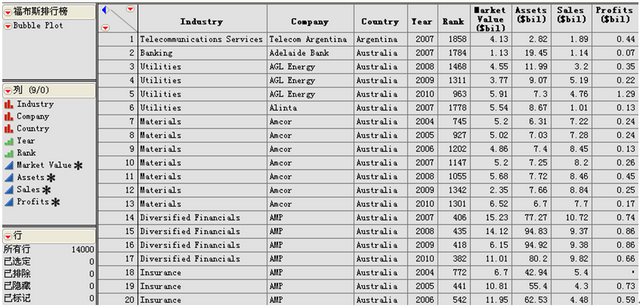
我们为了对全球经济的发展趋势和世界顶级公司的经营状况做一些研究,可以从公共网站上下载数据(如http://www.forbes.com/lists中的福布斯2000强名单),用JMP略作整理之后可以得到如表一所示的数据表,其中包含了上榜公司的名称、所属行业、所属国家、上榜年份、上榜排名、市场价值、资产额、销售额、利润额等9个变量,总计14000条记录(每年2000条,从2004年至2010年共7个年度)。现在的问题是:数据有了,其中到底隐藏着怎样的有价值的信息呢?我们又如何发现这些信息呢?
有人说:既然是连续型数据,又包含时间变量,应该用时间序列方法进行分析!的确,时间序列可以告诉我们变量随时间的变化,然而实际中我们所希望和可以得到的有价值的信息,往往远不止“随时间变化”这么简单,更何况,需要分析这些商业数据的用户常常并不清楚什么是“时间序列分析”方法。
还有人说:用一些传统的图形工具,比如折线图、柱状图、饼图等等来分析,不就可以进行数据探索了吗?这种方法似乎是可行的,但这些数据中有不少类别变量,他们的分类水平很多(例如年份跨越7年,行业分为30个,国家有75个之多,公司名称更是多达3505个),这样一来,光作图可能就让我们筋疲力尽了,“数据探索”又从何谈起?
表一 经JMP软件整理的福布斯2000强排行数据
什么方法才能很好地探索这些数据,从中发现我们所期望的、甚至意想不到的重要信息呢?我们应该从哪里着手分析才能找到这些信息呢?我们来尝试运用现代EDA中的可视 化技术“泡泡图”来边看边想。在JMP软件的帮助下,我们可以很快得到类似图一的图形,其中的横轴代表公司的市值,纵轴代表公司的销售额,泡泡的大小代表公司的利润额,泡泡的颜色代表公司所属的行业。最有意义的是,所有的泡泡并不是静止不动的,它们的位置、大小等都会随着年度的变化而动态变化。与此同时,整个变化的历史轨迹线也会在图中显示出来。
这样一来,我们就可以直观地发现一些明显的数据特征。就拿图中标识出来的两家知名公司来说。我们会发现通用电气General Electric的经营业绩比较稳定,而埃克森美孚Exxon Mobil就相对显得大起大落一些。虽然两者有明显不同,但自2008年起,市场价值均有显著的回落,这应当与当时席卷全球的经济危机有关。
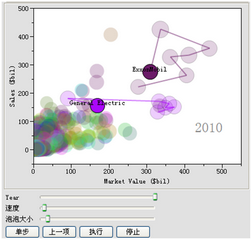
图一 基于JMP软件生成的动态泡泡图
有人在发现这些特征后会迸出一些新的想法:通用电气、埃克森美孚都是美国的企业,中国企业的表现又如何的呢?我们可以在使用“泡泡图”的同时,在JMP中调用“数据筛选”功能就可以得到类似图三的界面。
从中可以清晰地观察到,自2004年以来的7年间,共有392个次的中国企业登上了福布斯排行榜。虽然在数量上、市值、销售额等经营指标上与世界顶级企业有一定差距,但以中石油Petro China、中石化Sinopec China Petroleum等位代表的一批国有大型企业发展速度很快,令世界瞩目。
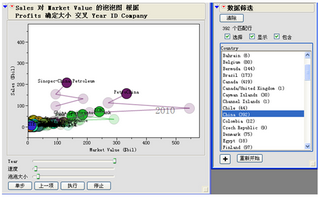
图二 JMP软件中动态泡泡图与数据筛选的配合使用
实际上,探索性数据分析还远远不止这些。分析人士完全可以在数据分析的初期不受太多理论条件的束缚,充分展开想象的翅膀,多角度、多层面地对现有数据的规律进行可视化的探索,新的线索往往就会自然而然地出现了,为下一步的统计建模与预测等精细化分析奠定良好的基础。
总之,探索性数据分析强调灵活地探求线索和证据,重在发现数据中可能隐藏着的有价值的信息,比如数据的分布模式、变化趋势,可能的交互影响,异常变化等等,而传统的统计方法则侧重于评估已经发现的证据,通常要求分析人员具备一定的统计学基础。根据不同的业务目的和数据资源选用不同的技术,或者综合使用这两类技术,将会使我们更快地获得更多的发现。对于大都不具备统计学功底但数据分析任务却越来越多的企业人员(如市场分析人员、质量管理人员等)来说,重视、学习并用好探索性数据分析往往能事半功倍。