
研究背景
WEB应用安全现状
随着互联网的发展,金融网上交易、政府电子政务、企业门户网站、社区论坛、电子商务等各类基于HTML文件格式的信息共享平台(WEB应用系统)越发完善,深入到人们生活中的点点滴滴。然而WEB应用共享平台为我们的生活带来便利的同时,也面临着前所未有的挑战:WEB应用系统直接面向Internet,以WEB应用系统为跳板入侵服务器甚至控制整个内网系统的攻击行为已成为最普遍的攻击手段。据Gartner的最新调查,目前75%以上的攻击行为都基于WEB应用层面而非网络层面;同时数据显示,三分之二的WEB站点都相当脆弱,易受攻击。
据中国互联网应急中心最新统计显示,2009年我国大陆地区政府网页遭篡改事件呈大幅增长趋势,被篡改网站的数量就达到52225个。2009年8月份,公安部对国内政府网站的进行安全大检查,发现40%存在严重安全漏洞,包括SQL注入、跨站脚本漏洞等。由此导致的网页篡改、网页挂马、机密数据外泄等安全事件频繁发生,不但严重影响对外形象,有时甚至会造成巨大的经济损失,或者严重的社会问题,严重危及国家安全和人民利益。
网页篡改:一些不法分子的重点攻击对象。组织门户网站一旦被篡改(加入一些敏感的显性内容),引发较大的影响,严重甚至造成政治事件。
网页挂马:网页内容表面上没有任何异常,实际被偷偷的挂上了木马程序。网页挂马未必会给网站带来直接损害,但却会给浏览网站的用户带来巨大损失。网站一旦被挂马,其权威性和公信力将会受到打击。
机密数据外泄:在线业务系统中,总是需要保存一些企业、公众的相关资料,这些资料往往涉及到企业秘密和个人隐私,一旦泄露,会造成企业或个人的利益受损,可能会给单位带来严重的法律纠纷。
传统安全防护方法
企业 WEB 应用的各个层面,都已使用不同的技术来确保安全性。为了保护客户端机器的安全,用户会安装防病毒软件;为了保证用户数据传输到企业 WEB 服务器的传输安全,通信层通常会使用 SSL技术加密数据;防火墙和 IDS/IPS来保证仅允许特定的访问,不必要暴露的端口和非法的访问,在这里都会被阻止;同时企业采用一定的身份认证机制授权用户访问 WEB 应用。
但是,即便有防病毒保护、防火墙和 IDS/IPS,企业仍然不得不允许一部分的通讯经过防火墙,保护措施可以关闭不必要暴露的端口,但是 WEB 应用所必须的端口,必须开放。顺利通过的这部分通讯,可能是善意的,也可能是恶意的,很难辨别。同时,WEB 应用是由软件构成的,那么,它一定会包含漏洞,这些漏洞可能被恶意的用户利用,他们通过执行各种恶意的操作,或者偷窃、或者操控、或者破坏 WEB 应用中的重要信息。
本文研究观点
网站是否存在WEB 应用程序漏洞,往往是被入侵后才能察觉;如何在攻击发动之前主动发现WEB应用程序漏洞?答案就是:主动防御,即利用WEB应用弱点扫描技术,主动实现对WEB应用的安全防护。
本文主要针对B/S架构WEB应用系统中典型漏洞、流行的攻击技术、AJAX的隐藏资源获取、验证码图片识别等进行研究,提出了一种新的面向WEB的漏洞检测技术,能够较完整得提取出AJAX的资源,有效识别验证码。
WEB应用风险扫描架构
WEB应用风险扫描技术架构主要分为URL获取层、检测层、取证与深度评估层三个层次,其中:
URL获取层:主要通过网络爬虫方式获取需要检测的所有URL,并提交至检测层进行风险检测;
风险检测层:对URL获取层所提交的所有URL页面进行SQL注入、跨站脚本、文件上传等主流WEB应用安全漏洞进行检测,并将存在安全漏洞的页面和漏洞类型提交至取证与深度评估层;
取证与深度评估层:针对存在安全漏洞的页面,进行深度测试,获取所对应安全漏洞的显性表现,(如风险检测层检测出该网站存在SQL注入漏洞,则至少需可获取该网站的数据库类型);作为该漏洞存在的证据。
网络爬虫技术—URL获取
网络爬虫是一个自动提取网页的程序,它通过指定的域名,从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
网络爬虫的工作流程较为复杂,首先根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,根据搜索策略从队列中选择下一步要抓取的网页URL,并重复,直到达到预设的停止条件。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询、检索和取证及报表生成时做为源数据。
为了更加高速、有效地获取网站中所有的URL链接,在本WEB应用风险扫描技术研究中,所采用的网络爬虫技术着重解决以下三个问题:
(1) 对抓取目标的描述或定义;
(2) 对网页和数据的分析与过滤;
(3) 对URL的搜索策略。
网页抓取目标
网页弱点爬虫对抓取目标的描述或定义基于目标网页特征抓取、存储并索引,对象是网站的网页;通过用户行为确定的抓取目标样例,其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,以及网页代码的结构特征等。
网页分析算法
基于网页内容的分析算法指的是利用网页内容(文本、数据等资源)特征进行的网页评价。该算法从原来的较为单纯的文本检索方法,发展为涵盖网页数据抽取、机器学习、数据挖掘、语义理解等多种方法的综合应用。根据网页数据形式的不同,将基于网页内容的分析算法,归纳以下三类:第一种针对以文本和超链接为主的无结构或结构很简单的网页;第二种针对从结构化的数据源动态生成的页面,其数据不能直接批量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵循一定模式或风格,且可以直接访问。
网页抓取策略
爬虫的抓取策略目前普遍的采用的方法有:深度优先、广度优先、最佳优先三种。由于深度优先在很多情况下会导致爬虫的陷入(trapped)问题,网页弱点爬虫目前采用的是深度优先和最佳优先方法组合方法。
深度优先搜索策略:指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。网页弱点爬虫采用深度优先搜索方法为覆盖指定网站存在弱点的网页。其基本思想是认为与初始URL在一定链接距离内的网页具有弱点相关性的概率很大;并采用将深度优先搜索与网页过滤技术结合使用,先用深度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低,因此网页弱点爬虫采用了最佳优先搜索策略来弥补这个缺点。
最佳优先搜索策略:最佳优先搜索策略采用基于网页内容的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。它只访问经过网页分析算法预测为“有用”的网页。
漏洞检测技术—风险检测
主要WEB应用漏洞
OWASP十大安全威胁
开放式WEB应用程序安全项目(OWASP,Open Web Application Security Project)是一个组织,它提供有关计算机和互联网应用程序的公正、实际、有成本效益的信息。其目的是协助个人、企业和机构来发现和使用可信赖软件。美国联邦贸易委员会(FTC)强烈建议所有企业需遵循OWASP所发布的十大Web弱点防护守则、美国国防部亦列为最佳实务,国际信用卡资料安全技术PCI标准更将其列为必须采用有效措施进行针对性防范。

图1 2010年OWASP十大安全威胁

CWE/SANS 25大危险编程错误
一般弱点列举(Common Weakness Enumeration CWE)是由美国国家安全局首先倡议的战略行动,该行动的组织最近发布了《2010年CWE/SANS最危险的程序设计错误(PDF)》一文,其中列举了作者认为最严重的25种代码错误,同时也是软件最容易受到攻击的点。OWASP Top 10,所关注的是WEB应用程序的安全风险,而CWE的Top 25的覆盖范围更广,包括著名的缓冲区溢出缺陷。CWE还为程序员提供了编写更安全的代码所需要的更详细的内容。
WEB应用漏洞规则库
我们经过多年WEB应用安全领域的研究,结合国内外优秀组织的经典总结、描述以及验证,建立起一套几乎涵盖所有可能带来安全威胁的WEB应用安全漏洞的丰富的WEB应用漏洞规则库,包括各个安全漏洞的产生原理、检测规则、可能危害、漏洞验证等等,通过自动化手段,对网络爬虫所获取到的网站页面进行逐一检测。随着安全漏洞的不断产生、攻击手段的不断演变,WEB应用漏洞规则库也不断获得充实和改进。
模拟渗透测试—取证与深度评估
模拟渗透测试
通常我们所理解的渗透测试,是指具有丰富安全经验的安全专家,在对目标系统一无所知的情况下,通过收集系统信息,进行具有针对性的安全攻击和入侵,获取系统管理权限、敏感信息的一个过程。这包括三个要素:丰富安全经验的安全专家(人)、系统漏洞(漏洞检测)、权限获取或信息获取(取证)。由于组织内部一般并不具备具有专业渗透技术的安全专家,所以通常依靠于第三方安全公司。渗透测试的过程中,虽然签署了一系列的保密协议,但是不可避免地会发生组织内部信息泄露的风险。
结合大量优秀安全专家的渗透测试经验,以及对各类WEB应用安全漏洞的显性分析(即如果存在该漏洞,其具体表现是什么),在完成网站中各个页面的漏洞检测后,对所存在的安全漏洞进行验证,即获取相应的权限或信息,达到模拟渗透测试的效果,不仅可以大大降低漏洞检测的误报率,准确呈现该漏洞的存在和取证;而且可以在一定程度上替代第三方的渗透测试人员,自主进行安全扫描,降低信息泄露的风险。
安全漏洞取证分析
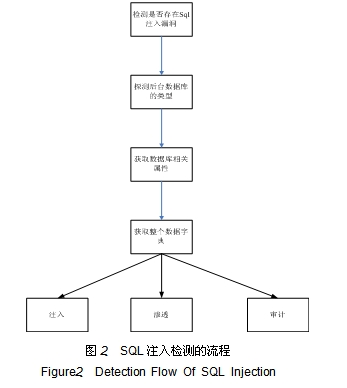
对安全漏洞的取证分析,在此以SQL注入漏洞为例进行简要描述。
SQL注入类型根据原理可以分为以下几类:数值型、字符型、搜索型、错误型、杂项型。在检测出相关注入漏洞后, 根据不同后台数据库, 采用不同的数据库注入策略包来进行进一步的取证和渗透。图2讲述了SQL注入检测的流程:通过网络爬虫获取的URL,成为SQL注入检测的输入,通过图2流程完成SQL注入、渗透和审计。
参考文献
[1] 胡勇 网络信息系统风险评估方法研究 四川大学,2007.
[2] 程建华 信息安全风险管理、评估与控制研究 吉林大学 2008.
[3] 陈光 信息系统信息安全风险管理方法研究 国防科学技术大学 2006.
[4] 安永新 基于风险的Web应用测试研究 重庆大学 2002.
[5] 黄明,梁旭 ASP信息系统设计与开发实例 机械工业出版社 2004
[6] 启明工作室 ASP网络应用系统实用开发技术 人民邮电出版社 2004
[7] S.Raghavan and H.Garcia- Molina. Crawling the hidden web [C]. Proceedings of the 27th International Conference on Very Large DataBases (VLDB), 2001.
[8] L.Barbosa and J.Freire. Anadaptive crawler for locating hidden-web entry points [C]. Proc. of the 16th international conference on World Wide Web, 2007:441-450.
[9] Improving Web Application Security Using New 2010 OWASP Top 10 Risk Model: Best Practices for Mitigating Online Vulnerabilities and Threats
[10] 2010 CWE/SANS Top 25 Most Dangerous Programming Errors

杭州安恒信息技术有限公司总裁 范渊