
对于中国工程师来说,利用实时Linux开发嵌入式应用程序是他们面临的困难之一,本文以RTLinux为例,并结合最为业界关注的是RTAI进行讨论,尽管这两种实现方式在句法细节上存在差异,但工作方式基本一样,因此所讲述的内容对两者都适用。
在实时任务与用户进程相互通信的过程中,有些实时应用程序无需任何用户界面即可在后台平静地运行,然而,越来越多的实时应用程序确实需要一个用户界面及其它系统功能,如文件操作或联网等,所有这些功能都必须在用户空间内运行。问题是,用户空间操作是非确定性的,而且与实时操作不兼容。
幸运的是实时Linux具有一种可在时间上减弱实时与非实时操作的机制,这种机制表现为一种称为实时FIFO的驱动程序。当insmod将rtl_fifo.o驱动程序插入Linux内核时,该驱动程序将自己注册为RTLinux的一部分,并成为Linux驱动程序。一旦插入Linux内核,用户空间进程和实时任务都可使用实时Linux FIFO。
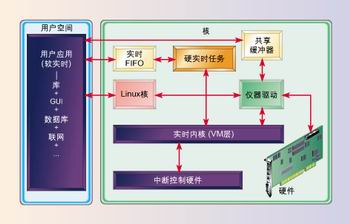
在深入探讨实时FIFO的细节之前,还要回顾一下实时应用程序结构的某些部分(图1)。有效的嵌入式应用程序设计方法是将实时部分与固有的非实时功能分离开来(表1)。如果应用程序的任一部分,如用户界面、图形、数据库或网络仅需软实时性能,最好是将该部分写入用户空间。然后,仅将必须满足时序要求的那部分写成实时任务。
注意,RTLinux(PSC,便携式信号编码)和RTAI(LXRT,Linux实时扩展)的最新版本已采用了一种可在用户空间执行软和硬实时任务的方法。
任何硬实时任务都是在RTLinux的控制下运行的,该任务一般可执行周期性任务、处理中断并与I/O设备驱动程序通信,以采集或输出模拟和数字信息。当实时任务需要告诉用户进程有一个事件将发生时,它便将这一消息送给实时FIFO。每一个FIFO都是在一个方向上传送数据:从实时任务到用户空间,或反之。因此,双向通信需要使用两个FIFO。任何读出或写入实时任务一侧的操作都是非模块操作,因此rtf_put()和rtf_get()都立即返回,而不管FIFO状态是什么。
从应用程序一侧来看,FIFO就像一个常规文件。缺省情况下,RTLinux安装程序将在/dev目录下创建6?个实时FIFO节点;如果需要,还必须自己创建新的节点。例如,要创建/dev/rtf80,需采用如下命令:
=========================
mknod c 150 80;
chmod 0666 /dev/rtf80
=========================
其中,150是实时FIFO主数,而80是rtf80的次数。
从用户进程的角度看,实时FIFO可执行标准文件操作。从实时任务来看,FIFO有两种通信方式:直接调用RTLinux FIFO功能,或将FIFO作为一个RTLinux设备驱动程序,并使用open()、close()、read()和write()操作。要想将FIFO作为一个设备驱动程序,就必须将rtl_conf.h中的配置变量CONFIG_RTL_POSIX_IO设定为1。
rtf_create_handler()可设置处理程序功能。每次Linux进程读或写FIFO时,rtl_fifo驱动程序都要调用该处理程序。应注意的是,该处理程序驻留在Linux内核,因此当Linux需要调用时,从该处理程序进行任何内核调用都是安全的。从该处理程序到实时任务间的最好通信方法是使用旗语或线程同步功能。最后,FIFO驱动程序还必须对内核存储器进行配置。因此,实时线程内的rtf_create()不应调用。相反,可调用init_module()中的rtf_create()功能及cleanup_module()中的rtf_destroy()功能。
例如,列表1给出了一个采用两个FIFO的简单数据采集应用程序的实时部分。两个FIFO都是在init_module()创建,并赋予minor numbers 为1和2。在调用rtf_create(minor, size)之前,该程序在已创建该FIFO的情况下调用rtf_destroy(minor)。这种情况就是另一个模块在开发过程中未被调用。然后,调用rtf_create_handler(ID, &pd_do_aout)以注册带该实时FIFO的数据采集模拟输出功能pd_do_aout()。注意,创建实时线程pp_thread_ep()是因为它是周期性的,其间隔为1/100秒。
每次周期性线程得到系统控制权后,它就调用rtf_put(ID,dataptr,size)以便将数据插入minor number为2的FIFO。Linux进程打开/dev/rtf2,从实时FIFO中读取并显示所采集的数据。该进程还打开/dev/rtf1,将数据写入其它实时FIFO。当用户移动屏幕滑动器以改变模拟输出电压时,进程就向该FIFO写入一个新的值。RTLinux便调用pd_do_aout()处理程序,随后pd_do_aout()利用rtf_get()从FIFO获得值,并调用实际的硬件驱动程序以设置模拟输出的电压。可以看到,实时任务和用户进程是异步使用FIFO的。

任务间的存储器共享
FIFO为用户进程和实时任务的连接提供了一种方便的机制,但将它们作为消息队列更合适。比如,一个实时线程可利用FIFO记录测试结果,然后用户进程就可读取该结果,并将之存入数据库文件。
许多数据采集应用程序涉及到内核及用户空间之间的大量数据。Linux内核v. 2.2.x并没有为这些空间的数据共享提供任何机制,但v. 2.4.0版本预计会包括kiobuf结构。为解决现有稳定内核的这个缺点,RTLinux包括mbuff驱动程序。该驱动程序可利用vmalloc()分配虚拟内核存储器的已命名存储器区域,它采用的存储器分配和页面锁定技巧跟大多数Linux中bttv帧抓取器(frame-grabber)驱动程序所用的一样。
更具体地说,mbuff一页一页地将虚拟内存锁定到实际的物理内存页面。任何实时或内核任务,或用户进程在任何时间都可访问该存储器。通过将虚拟内存页面锁定到物理内存页面,mbuff可确保所分配的页面永久驻留在物理内存,而且不会发生页面错误。换言之,当实时或内核进程访问所分配的存储器时,它可确保VMM不被调用。注意:由于实时任务执行期间实时Linux冻结标准内核的执行,任何对VMM的调用都会引起系统暂停。如果它要访问并不位于物理RAM内的虚拟存储页面,那么即使正常的Linux内核驱动程序也会引起系统故障。
由于mbuff是一种Linux驱动程序,其功能可通过设备节点/dev/mbuff实现。该节点可显示几个录入点,其中包括可将内核空间地址映射到用户空间的mmap()。它还可以利用录入点ioctl()来控制。然而,并不需要复杂的结构及直接调用ioctl。相反,mbuff可为ioctl()调用提供一个包裹,而且仅仅调用两个简单的功能即可配置和释放共享的存储缓冲器。
当然,不能从实时任务调用mbuff驱动程序,因为该驱动程序所调用的虚拟存储器分配功能本身是不确定性操作。分配共享存储器所需的时间依赖于主系统的存储器容量以及CPU速度、磁盘驱动器性能和存储器分配的现有状态。因此,只能从模块的Linux内核一侧来分配共享存储器,比如从init_module()或一个ioctl()请求开始。
那么,一个共享缓冲器到底能分配多少存储器呢?如果不是任务繁重的服务器或图形应用,建议至少为Linux保留8MB存储空间。为了获得优化的配置,可在限制存储器大小的同时测量实时应用程序的性能,以确定需要多少存储空间。
列表2给出了如何从实时任务和用户进程方面访问共享的存储器。内核模块和用户任务采用同样的功能集。当然,要想使用insmod mbuff.o,还必须将之置于Linux内核中。例如,mbuff_alloc(“buf_name”, size)可将符号名buf_name分配给一个缓冲器,而mbuff_free(“buf_name”, mbuf)可将之释放。
当第一次调用带有符号缓冲器名的mbuff_alloc()时,mbuff执行实际的存储器分配。而当从内核模块或用户进程再次调用该功能时,它只是简单地增加使用数(usage count)及将指针返回现有的缓冲器。每次调用mbuff_free()都会减少使用数,直至为零,这时mbuff就去分配带符号名的缓冲器。这种方法从多个内核模块和用户进程获得一个指向同一共享缓冲器的指针,从而解决了问题。它还可确保共享缓冲器一直有效,直到最后的应用程序释放它。请注意,是实时内核还是用户进程执行实际的buf1配置依赖于谁先获得控制权。
还有一个“笨”方法可在实时应用程序、内核模块和用户应用程序间共享存储器。对于嵌入式应用,该方法还是可以接受的。例如,如果PC带有128MB RAM,可将线搜索路径=“mem=120m”添加进lilo.conf文件(列表3)。当启动带有Linux内核和RTLinux 2.3的系统时,Linux仅使用120MB内存。OS也不用剩下的8MB内存(物理地址为0x7F00000到0x7FFFFFF),而是留给在OS下运行的各种任务共享。要想从用户进程获取存储器地址并访问预留的存储器,必须用O_RDWR访问模式来打开/dev/mem驱动程序,然后利用mmap()保留存储器(列表4)。而从实时模块或内核驱动程序一侧进行,则必须使用ioremap(0x7F00000, 0x100000)才能获取这8MB (0x100000字节)预留内存。
这种方法有利有弊。既不能通过预留内存的所有权,也不能通过读或写来获取控制权。正确地配置和释放大量内存的机制尚未问世。另外,无论实时进程是否需要,该内存都不能为Linux所用。
也许存储器共享笨方法的唯一适用场合是专为特定应用而定制的小型嵌入式系统,因为此时可为小型化而放弃使用mbuff驱动程序。
对于中国工程师来说,利用实时Linux开发嵌入式应用程序是他们面临的困难之一,本文以RTLinux为例,并结合最为业界关注的是RTAI进行讨论,尽管这两种实现方式在句法细节上存在差异,但工作方式基本一样,因此所讲述的内容对两者都适用。
在实时任务与用户进程相互通信的过程中,有些实时应用程序无需任何用户界面即可在后台平静地运行,然而,越来越多的实时应用程序确实需要一个用户界面及其它系统功能,如文件操作或联网等,所有这些功能都必须在用户空间内运行。问题是,用户空间操作是非确定性的,而且与实时操作不兼容。
幸运的是实时Linux具有一种可在时间上减弱实时与非实时操作的机制,这种机制表现为一种称为实时FIFO的驱动程序。当insmod将rtl_fifo.o驱动程序插入Linux内核时,该驱动程序将自己注册为RTLinux的一部分,并成为Linux驱动程序。一旦插入Linux内核,用户空间进程和实时任务都可使用实时Linux FIFO。
在深入探讨实时FIFO的细节之前,还要回顾一下实时应用程序结构的某些部分(图1)。有效的嵌入式应用程序设计方法是将实时部分与固有的非实时功能分离开来(表1)。如果应用程序的任一部分,如用户界面、图形、数据库或网络仅需软实时性能,最好是将该部分写入用户空间。然后,仅将必须满足时序要求的那部分写成实时任务。
注意,RTLinux(PSC,便携式信号编码)和RTAI(LXRT,Linux实时扩展)的最新版本已采用了一种可在用户空间执行软和硬实时任务的方法。
任何硬实时任务都是在RTLinux的控制下运行的,该任务一般可执行周期性任务、处理中断并与I/O设备驱动程序通信,以采集或输出模拟和数字信息。当实时任务需要告诉用户进程有一个事件将发生时,它便将这一消息送给实时FIFO。每一个FIFO都是在一个方向上传送数据:从实时任务到用户空间,或反之。因此,双向通信需要使用两个FIFO。任何读出或写入实时任务一侧的操作都是非模块操作,因此rtf_put()和rtf_get()都立即返回,而不管FIFO状态是什么。
从应用程序一侧来看,FIFO就像一个常规文件。缺省情况下,RTLinux安装程序将在/dev目录下创建6?个实时FIFO节点;如果需要,还必须自己创建新的节点。例如,要创建/dev/rtf80,需采用如下命令:
=========================
mknod c 150 80;
chmod 0666 /dev/rtf80
=========================
其中,150是实时FIFO主数,而80是rtf80的次数。
从用户进程的角度看,实时FIFO可执行标准文件操作。从实时任务来看,FIFO有两种通信方式:直接调用RTLinux FIFO功能,或将FIFO作为一个RTLinux设备驱动程序,并使用open()、close()、read()和write()操作。要想将FIFO作为一个设备驱动程序,就必须将rtl_conf.h中的配置变量CONFIG_RTL_POSIX_IO设定为1。
rtf_create_handler()可设置处理程序功能。每次Linux进程读或写FIFO时,rtl_fifo驱动程序都要调用该处理程序。应注意的是,该处理程序驻留在Linux内核,因此当Linux需要调用时,从该处理程序进行任何内核调用都是安全的。从该处理程序到实时任务间的最好通信方法是使用旗语或线程同步功能。最后,FIFO驱动程序还必须对内核存储器进行配置。因此,实时线程内的rtf_create()不应调用。相反,可调用init_module()中的rtf_create()功能及cleanup_module()中的rtf_destroy()功能。
例如,列表1给出了一个采用两个FIFO的简单数据采集应用程序的实时部分。两个FIFO都是在init_module()创建,并赋予minor numbers 为1和2。在调用rtf_create(minor, size)之前,该程序在已创建该FIFO的情况下调用rtf_destroy(minor)。这种情况就是另一个模块在开发过程中未被调用。然后,调用rtf_create_handler(ID, &pd_do_aout)以注册带该实时FIFO的数据采集模拟输出功能pd_do_aout()。注意,创建实时线程pp_thread_ep()是因为它是周期性的,其间隔为1/100秒。
每次周期性线程得到系统控制权后,它就调用rtf_put(ID,dataptr,size)以便将数据插入minor number为2的FIFO。Linux进程打开/dev/rtf2,从实时FIFO中读取并显示所采集的数据。该进程还打开/dev/rtf1,将数据写入其它实时FIFO。当用户移动屏幕滑动器以改变模拟输出电压时,进程就向该FIFO写入一个新的值。RTLinux便调用pd_do_aout()处理程序,随后pd_do_aout()利用rtf_get()从FIFO获得值,并调用实际的硬件驱动程序以设置模拟输出的电压。可以看到,实时任务和用户进程是异步使用FIFO的。
任务间的存储器共享
FIFO为用户进程和实时任务的连接提供了一种方便的机制,但将它们作为消息队列更合适。比如,一个实时线程可利用FIFO记录测试结果,然后用户进程就可读取该结果,并将之存入数据库文件。
许多数据采集应用程序涉及到内核及用户空间之间的大量数据。Linux内核v. 2.2.x并没有为这些空间的数据共享提供任何机制,但v. 2.4.0版本预计会包括kiobuf结构。为解决现有稳定内核的这个缺点,RTLinux包括mbuff驱动程序。该驱动程序可利用vmalloc()分配虚拟内核存储器的已命名存储器区域,它采用的存储器分配和页面锁定技巧跟大多数Linux中bttv帧抓取器(frame-grabber)驱动程序所用的一样。
更具体地说,mbuff一页一页地将虚拟内存锁定到实际的物理内存页面。任何实时或内核任务,或用户进程在任何时间都可访问该存储器。通过将虚拟内存页面锁定到物理内存页面,mbuff可确保所分配的页面永久驻留在物理内存,而且不会发生页面错误。换言之,当实时或内核进程访问所分配的存储器时,它可确保VMM不被调用。注意:由于实时任务执行期间实时Linux冻结标准内核的执行,任何对VMM的调用都会引起系统暂停。如果它要访问并不位于物理RAM内的虚拟存储页面,那么即使正常的Linux内核驱动程序也会引起系统故障。
由于mbuff是一种Linux驱动程序,其功能可通过设备节点/dev/mbuff实现。该节点可显示几个录入点,其中包括可将内核空间地址映射到用户空间的mmap()。它还可以利用录入点ioctl()来控制。然而,并不需要复杂的结构及直接调用ioctl。相反,mbuff可为ioctl()调用提供一个包裹,而且仅仅调用两个简单的功能即可配置和释放共享的存储缓冲器。
当然,不能从实时任务调用mbuff驱动程序,因为该驱动程序所调用的虚拟存储器分配功能本身是不确定性操作。分配共享存储器所需的时间依赖于主系统的存储器容量以及CPU速度、磁盘驱动器性能和存储器分配的现有状态。因此,只能从模块的Linux内核一侧来分配共享存储器,比如从init_module()或一个ioctl()请求开始。
那么,一个共享缓冲器到底能分配多少存储器呢?如果不是任务繁重的服务器或图形应用,建议至少为Linux保留8MB存储空间。为了获得优化的配置,可在限制存储器大小的同时测量实时应用程序的性能,以确定需要多少存储空间。
列表2给出了如何从实时任务和用户进程方面访问共享的存储器。内核模块和用户任务采用同样的功能集。当然,要想使用insmod mbuff.o,还必须将之置于Linux内核中。例如,mbuff_alloc(“buf_name”, size)可将符号名buf_name分配给一个缓冲器,而mbuff_free(“buf_name”, mbuf)可将之释放。
当第一次调用带有符号缓冲器名的mbuff_alloc()时,mbuff执行实际的存储器分配。而当从内核模块或用户进程再次调用该功能时,它只是简单地增加使用数(usage count)及将指针返回现有的缓冲器。每次调用mbuff_free()都会减少使用数,直至为零,这时mbuff就去分配带符号名的缓冲器。这种方法从多个内核模块和用户进程获得一个指向同一共享缓冲器的指针,从而解决了问题。它还可确保共享缓冲器一直有效,直到最后的应用程序释放它。请注意,是实时内核还是用户进程执行实际的buf1配置依赖于谁先获得控制权。
还有一个“笨”方法可在实时应用程序、内核模块和用户应用程序间共享存储器。对于嵌入式应用,该方法还是可以接受的。例如,如果PC带有128MB RAM,可将线搜索路径=“mem=120m”添加进lilo.conf文件(列表3)。当启动带有Linux内核和RTLinux 2.3的系统时,Linux仅使用120MB内存。OS也不用剩下的8MB内存(物理地址为0x7F00000到0x7FFFFFF),而是留给在OS下运行的各种任务共享。要想从用户进程获取存储器地址并访问预留的存储器,必须用O_RDWR访问模式来打开/dev/mem驱动程序,然后利用mmap()保留存储器(列表4)。而从实时模块或内核驱动程序一侧进行,则必须使用ioremap(0x7F00000, 0x100000)才能获取这8MB (0x100000字节)预留内存。
这种方法有利有弊。既不能通过预留内存的所有权,也不能通过读或写来获取控制权。正确地配置和释放大量内存的机制尚未问世。另外,无论实时进程是否需要,该内存都不能为Linux所用。
也许存储器共享笨方法的唯一适用场合是专为特定应用而定制的小型嵌入式系统,因为此时可为小型化而放弃使用mbuff驱动程序。
中断
RTLinux有两种中断:硬中断和软中断。软中断就是常规Linux内核中断,它的优点在于可无限制地使用Linux内核调用。这类中断作为硬中断处理的第二部分还是相当有用的(由参考文献5可获得更多有关Linux环境下中断处理的细节)。
硬(实时)中断是安装实时Linux的前提。要安装中断处理程序,先调用rtl_request_irq(。..),然后调用rtl_free_irq()释放它。依赖于不同的系统,实时Linux下硬(或实时)中断的延迟是15μs的数量级。较快的处理器具有较好的延迟。如果想在实时处理程序和常规Linux驱动程序中处理同一设备IRQ,必须为每一个硬中断单独设置IRQ。
列表5给出了安装实时中断处理程序的过程。RTLinux在执行实时中断处理程序时将禁止IRQ。应注意,该代码须在退出实时中断处理程序前调用rtl_hard_enable_irq()才能重新使能中断。
有两个问题影响直接从实时中断处理程序调用Linux内核功能:内核禁止所有中断及不定义执行内容。还应注意的是,这里也不能执行浮点操作。利用实时中断处理程序来控制线程执行是避免出现这些问题的好办法。本例采用pthread_wakeup_np()功能来唤醒一个实时线程。中断处理程序可处理即时的工作,余下的由该线程解决。
SMP结构的优点
实时Linux都支持多处理器架构。对称多处理器(SMP)结构采用了高级可编程中断控制器(APIC),奔腾级处理器都有片上本地APIC,可为本地处理器传送中断。SMP(甚至单处理器母板)都有I/O APIC,可收集来自外设的中断请求,并将它们传送给本地APIC。旧的8259 PIC速度很慢,所处理的中断向量数不充分,迫使设备共享中断,使得中断处理更慢。但是,APIC可解决这些问题。通过为每个设备请求设置一个特定的IRQ,系统可减少中断延迟,APIC还可加速同步代码。
实时Linux可充分利用APIC。在SMP系统中,实时调度程序利用APIC,而不是采用过时的8254芯片来完成时序分配。由于PC的兼容性,8254位于每一个ISA总线上,而且每一个再编程设备的调用都要占用处理器周期。一个千兆赫CPU要浪费数百个处理器周期来等待8MHz定时器(大约2.5μs)。APIC工作在总线频率,而且可立即执行所有的定时器操作,这意味着必须利用本地APIC时钟在AMP机器上获取更高的周期性频率(双P-III-500 CPU可在100kHz运行周期性实时线程,而无明显的性能损失)。
实时Linux能很好地执行多处理任务,它为每个CPU实施单独的进程。调用pthread_create()可创建一个在现有CPU上运行的线程。还可用pthread_attr_setcpu_np()将该线程分配给一个特定的CPU,以改变线程属性。在调用这一功能之前,必须首先初始化线程属性。
RTLinux v. 3包括reserve_cpu功能,可预留SMP平台上的一个CPU,专供RTLinux使用。它可运行于2.4x内核,RTAI也具有几乎同样的功能。
如果想将任务分给某一特定的CPU,请留意“pset”方案(http://isunix.it.ilstu.edu/thockin/pset/)。利用该内核可将一个SMP处理器专门分配给一个用户应用程序,甚至可从Linux处理器组中调用一个处理器专用于实时任务。
同步基元
早期的实时Linux没有同步基元。现在,POSIX型的旗语、互斥和信号在最新的实时Linux版本中都已出现。虽然在实时设计中采用这些同步基元还存在问题,但同步或用信号表示实时任务和用户应用程序很有意义,然而,这要求软件开发者具有高超的技能,这一问题已超出本文的讨论范围。
快速学习pthread_mutex_init()、pthread_mutex_lock()、pthread_mutex_trylock()、pthread_mutex_unlock()和pthread_mutex_destroy()等同步功能的最好方法是查看。/examples/mutex/mutex.c。特别要提醒的是。/examples/mutex/sema_test.c文件是学习旗语的很好起点。
实时Linux发展方向
实时Linux与Linux一样仍然处于不断发展之中。每一个新的版本都添加了更多的特性和功能。实时Linux正朝着更好的POSIX 1003.x实现方向发展,最新的特性包括用户空间进程的实时支持、互斥、信号、旗语、实时存储器管理和扩展的SMP支持等。如果还未确定下一个项目采用哪个实时系统,可下载一种实时Linux版本了解一下。其实,Linux已经是一种成熟的OS,而且具备实时扩展版本,它是嵌入式应用的最佳选择之一。
列表1:实时FIFO的使用。
#define IN_FIFO_ID 1
#define OUT_FIFO_ID 2
#define IN_FIFO_LENGTH 0x100
#define OUT_FIFO_LENGTH 0x100
// RT FIFO invokes this function every time the user process writes
// something into /dev/rtf1
int pd_do_aout(unsigned int fifo)
{
u32 ao_value;
while ((err = rtf_get(IN_FIFO_ID, &ao_value, sizeof(u32)))
== sizeof(u32))
{
pd_aout_write(board, ao_value);
}
if (err != 0) return -EINVAL; else return 0;
}
void *pp_thread_ep(void *rate) // our periodic thread
{
u16 ain_data;
。..
ret = pd_ain_read(board, &ain_data); // read value from analog in
// write to the output FIFO where user process can read it from /dev/rtf2
ret = rtf_put(OUT_FIFO_ID, &ain_data, sizeof(u16));
。.. process ret for return codes 。..
}
init_module(void)
{ 。..
// free up the resource, just in case
rtf_destroy(IN_FIFO_ID);
rtf_destroy(OUT_FIFO_ID);
// create fifos we can talk via /dev/rtf1 and /dev/rtf2
rtf_create(IN_FIFO_ID, IN_FIFO_LENGTH); // rt task 《- user process
rtf_create(OUT_FIFO_ID, OUT_FIFO_LENGTH); // rt task -》 user process
rtf_create_handler(IN_FIFO_ID, &pd_do_aout);
。..
}
cleanup_module(void)
{ 。..
rtf_destroy(IN_FIFO_ID); // free up the resource, just in case
rtf_destroy(OUT_FIFO_ID); // free up the resource, just in case
。..
}
列表2:利用mbuff共享存储器。
// user application
#include “mbuff.h”
。..
u16* buf1; // pointer to the buffer to store 16-bit samples
main (int argc,char *argv[])
{
。..
buf1 = (u16*) mbuff_alloc(“buf1”,0x100000);
if (buf1 == NULL) { // failure to allocate buffer }
sprintf((char*)buf1, “Hello, rt-task!\n”); // put some data into buffer
// now you can tell your realtime module to that you wrote
// something to the buffer, say, using RT FIFO
。..
mbuff_free(“buf1”, (void*)buf1); // free buffer when you don‘t need it
}
// realtime module
#include “mbuff.h”
。..
u16* buf1; // pointer to the buffer to store 16-bit samples
init_module(void) // allocate shared buffer during init of realtime module
{
// allocate 1MB buffer named “buf1”
buf1 = (u16*) mbuff_alloc(“buf1”, 0x100000);
if (buf1 == NULL) { failure to allocate buffer }
。..
}
cleanup_module(void) // deallocate buffer during cleanup of realtime module
{ mbuff_free(“buf1”, buf1); // free it
。..
}
列表3:设定可在lilo.conf文件中使用的存储器内核数量。
。..
image=/boot/vmlinuz_2_2_14.rtl_2_3
append=“mem=120m”
root=/dev/hda2
label=RTL.2.3
。..
列表4:设置并采用笨方法共享内存。
// User space code:
if (fd = open(“/dev/mem”, O_RDWR)) 《 0) { 。..oops! error }
rtshm_ptr = (char * ) mmap (0, 0x100000, PROT_READ | PROT_WRITE, MAP_SHARED,
fd, 0x7F00000);
if (rtshm_ptr == MAP_FAILED) { 。..oops! error }
else { 。..use it }
// and in your real-time module:
rtshmbase = (long*) ioremap(0x7f00000, 0x100000);
列表5:获得中断向量。
// thread used as deferred procedure call created in init_module
void *pp_thread_ep(void* arg)
{
while (1)
{
pthread_wait_np(); // wait to be woken up.。.
// process interrupt now in realtime kernel context
。..
}
}
// interrupt handler
unsigned int irq_handler(unsigned int irq, struct pt_regs *regs)
{
pthread_wakeup_np(pp_thread); // wake up thread to do IRQ post-processing
rtl_hard_enable_irq(IRQ_LINE); // re-enable IRQ
return 0;
}
int init_module(void)
{
// create thread pp_thread to wake up by interrupt handler
。..
rtl_request_irq(IRQ_LINE, irq_handler); // request.。.
rtl_hard_enable_irq(IRQ_LINE); // 。..and enable interrupt handler
}
void cleanup_module(void)
{
rtl_free_irq(IRQ_LINE);
// do the rest of clean=up sequence
}