
摘 要: 阐述了我国拥有自主知识产权的音视频编码技术标准——AVS标准的熵解码算法,介绍了基于AVS标准的熵解码器的设计。根据码流的特点划分硬件模块,采用筒形移位器结构提高解码并行性,应用Verilog硬件描述语言、EDA软件ModelSim仿真、QuartusII软件综合,并通过了Altera公司的Cyclone系列FPGA芯片的下载验证,证明该设计能够实现AVS码流的实时解码功能。
关键词: AVS;熵解码;可编程逻辑门阵列;Verilog 硬件描述语言
AVS标准是《信息技术 先进音视频编码》系列标准的简称,是我国具备自主知识产权的第二代信源编码标准。AVS标准包括系统、视频、音频、数字版权管理等四个主要技术标准和一致性测试等支撑标准。
目前音视频产业可以选择的信源编码标准有四个:MPEG-2、MPEG-4、AVC(也称JVT、H.264)和AVS。从制订者分,前三个标准是由MPEG专家组完成的,第四个是我国自主制定的。从发展阶段分,MPEG-2是第一代信源标准,其余三个为第二代标准。从主要技术指标——编码效率比较,MPEG-4是MPEG-2的1.4倍,AVS和AVC相当,都是MPEG-2的两倍以上。
AVC标准中,对预测残差有两种熵编码的方式:基于上下文的自适应变长码(CAVLC)和基于上下文的自适应二进制算数编码(CABAC);对于非预测残差,采用指数哥伦布码或CABAC编码,视编码器的设置而定[1]。
AVS标准所用的熵编码技术相比于以前有了很多改进,它的语法元素和残差系数是由定长码和指数哥伦布码构成的,其中指数哥伦布码和语法元素之间存在多种映射关系。
1 AVS标准熵解码算法描述
在整个AVS视频的解码过程中,熵解码模块位于系统的最前端,负责从压缩后的码流中解析出宏块头信息以及量化系数,供后续的帧内预测模块和帧间预测模块使用。而熵解码模块又可以大体分为两个部分:解析K阶指数哥伦布码部分和解析语法元素部分。
解析K阶指数哥伦布码时,首先从比特流的当前位置开始寻找第一个非零比特,并将找到的零比特个数记为leadingZeroBits,然后根据leadingZeroBits计算CodeNum。用伪代码描述如下:
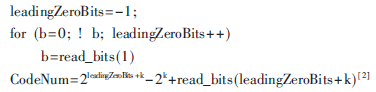
由于AVS视频中所有的语法元素以及经过变换和量化的残差系数都是以指数哥伦布码的形式映射成二进制码流的,因此在解析出K阶指数哥伦布码的CodeNum后,下一步就是要还原出各种语法元素和残差系数。
在AVS标准中规定了四种映射方式:ue(v)、se(v)、me(v)和ce(v)。其中ue(v)、se(v)和me(v)所描述的语法元素采用0阶的指数哥伦布码,ce(v)用来描述残差系数,可以采用0阶、1阶、2阶或者3阶指数哥伦布码。它们的解析过程如下:
ue(v):无符号直接映射,语法元素的值等于CodeNum;
se(v):有符号映射,映射关系为:当CodeNum=k时,语法元素值为(-1)k+1×Ceil(k÷2)
me(v):分为MbCBP和MbCBP422两种模式,分别根据CodeNum的值,查找相对应的表来得到语法元素的值。
ce(v):ce(v)描述的语法元素可以采用0阶、1阶、2阶或3阶指数哥伦布码进行解析,还有19个相关的码表,对于阶数的确定规则以及码表的切换规则,在AVS标准中都有详细的说明。解析时,首先语法元素trans_coefficient等于CodeNum,如果trans_coefficient小于59,可以根据trans_coefficient的值查找相关的码表得到残差系数;如果trans_coefficient大于等于59,解析下一个ce(v)语法元素,得到一个新的CodeNum,escape_level_diff等于CodeNum,然后根据trans_coefficient和escape_level_diff求得残差系数[3]。
2 熵解码器的硬件设计
由于熵解码器位于整个解码结构的最前端,所有后续模块中需要用到的数据都是熵解码模块从原始码流中解析出来的,因此熵解码器性能的优劣直接影响到整个AVS视频解码器的性能。
从前面的介绍中可以了解到,经过指数哥伦布编码后形成的码流中,每个码的码长不固定,而且前后具有很大的相关性,这样在解码时就必须逐位读取数据,解析完一个码字后才能解析下一个码字。这种串行解码的方式严重限制了熵解码器的性能,所以需要找到一种能够并行解码的方式。这里的并行解码并不是指同时对好几个码进行解码,而是针对一个变长码的多个位来说的。具体来说就是一次读入N位数据,通过比较操作,得到码长,使得解码可以在确定的时间长度内进行,而不是随着码长的不同而变化。显然,这将提高硬件的复杂度,但是换来了解码速度的提高[4]。
整个熵解码器可以分为四个模块:数据准备模块、解指数哥伦布码模块、语法元素解析模块和解码控制模块。硬件结构如图1所示。

下面通过分析码流数据的解析过程来逐个说明各个模块的功能和实现。
2.1 数据准备模块
这个模块的功能是为后边的解指数哥伦布码模块准备好未解码数据,要求解指数哥伦布码模块解完一个码,数据准备模块就要在码流中将解完的码移走,并准备好下一个要解的码字送给下一模块。硬件结构如图2所示。
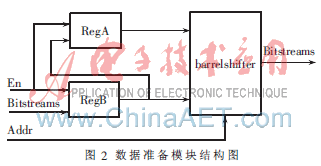
RegA和RegB是两个32位的寄存器,其中RegB直接从未解码码流中读取数据,RegA则接收RegB中的数据,两个寄存器共同组成barrelshifter的输入。
barrelshifter是一个64位输入、32位输出的暂存器,每次输出都将刚解完的一个码字移出,以保证输出的32位数据中最低位为下一个要解码的码字的开始。移位的位数由输入的地址Addr来决定,即输出64位输入的[Addr,Addr+31]位。
当En信号有效时,更新数据,将RegB中的数据存到RegA中,再从码流中读取新的32位数据,存到RegB中。其中Addr和En信号由解指数哥伦布码模块给出。
2.2解指数哥伦布码模块
这个模块的功能是接收上一模块准备好的未解码数据,计算出从最低位开始的一个指数哥伦布码的CodeNum,并根据这个码的码长算出筒形移位器的移位地址。模块结构如图3所示。

由于上一个模块准备好的未解码码流是一个以新的指数哥伦布码的开始为最低位的32位码流,因此要计算出这个码的CodeNum,首先要算出这个码的码长,然后在这32位数据中截取出这个码字,才可以计算它的CodeNum。根据指数哥伦布码的结构,码长与这个码的前导零个数M和阶数K有密切关系,可以总结出一个公式:CodeL=2×M+K+1。码长计算模块就是根据这个原理来计算码长的,首先通过一组比较器检测从最低位开始有几个零,然后根据上述公式得到码长。对于阶数K,解ue(v)、me(v)和se(v)语法元素时,阶数K为0。解ce(v)时,当前解码码字的阶数在解码上一个码字时可以得出。
累加器模块是一个模为32的加法器,将码长计算模块计算出来的码长CodeL累加到上一次的移位地址上,得到一个新的移位地址,筒形移位器根据这个新的地址,将本次解码的码字移出,准备好下一个未解码码流。En为进位输出,当累加器的En为1时,说明已经解完了32位数据,这时需要对RegA和RegB进行数据更新。
计算码字的CodeNum时,首先根据码长计算模块算出来的码字长度,从上一模块准备好的未解码码流中把本次要解码的码字截取出来,抛弃无用的位,然后再根据公式CodeNum=2leadingZeroBits+k-2k+read_bits(leadingZeroBits+k)计算这个码字的CodeNum。显然这个公式太过复杂,不适合直接硬件化,但是经过分析公式以及指数哥伦布码的结构,可以改造一下公式。因为指数哥伦布码的结构为前面M个前导0,中间一个1,后面M+K位数据组成,而read_bits(leadingZeroBits+k)即为后面M+K位数据的码字值,2leadingZeroBits+k正好为中间那个1的码字值,所以一个码字的CodeNum就等于这个码字的码字值减去2k,这样对CodeNum的计算就大大简化了。
2.3 语法元素解析模块
顾名思义,这个模块就是最终解析出语法元素含义的模块,它接收上一模块计算出来的CodeNum值,然后主要通过查表的方式解析出这个码字所代表的语法元素含义,结构如图 4所示。
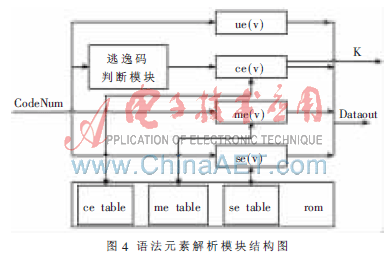
这里主要介绍下最复杂的ce(v)部分的解析过程。
逃逸码判断模块:在解析ce(v)语法元素时,首先要判断是否为逃逸码,即CodeNum<59时,按照正常ce(v)语法元素解析规则解析;CodeNum≥59时,下一码字为逃逸码,则按照逃逸码解析规则解析。
ce(v)语法元素解析模块:正常ce(v)语法元素的解析过程为:以CodeNum的值为索引,查找当前码表,得到(run、level),然后根据标准中的码表切换规则进行码表切换,并得到下一码字的阶数K。解析逃逸码的解析过程为:令transcoefficient等于CodeNum,得到run=(transcoefficient-59)/2。以当前码表为索引,查表得到对应的MaxRun,如果run>MaxRun,则RefAbslevel=1,否则以run为索引查当前码表,得到RefAbslevel。解析下一个语法元素,得到一个新的Codenum,escape_level_diff等于CodeNum。如果transcoefficient为奇数,则level等于-(RefAbslevel+escape_level_diff);如果transcoefficient为偶数,则level等于(RefAbslevel+escape_level_diff)。最后再按照标准中的码表切换规则进行码表切换,等待解析下一个语法元素。
3 测试与验证
将本文提出的熵解码器结构设计用Verilog HDL实现,用ModelSim在综合前进行仿真,仿真模型如图5所示。AVS标准参考软件产生测试码流数据,将测试码流数据输入硬件描述语言仿真模型,然后将输出数据与标准输出对比,实现仿真功能。经过测试,硬件熵解码后的数据与软件熵解码后的数据完全一致。
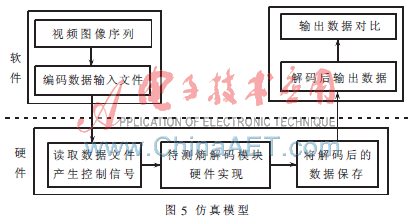
整个电路使用Altera的QuartusII 9.0软件进行综合,使用的LE总数为1 906个。变字长解码器模块是AVS解码器的一部分,综合后与其他部分集成,通过了FPGA验证,采用CycloneII系列的EP2C35型FPGA,其最高频率能达到94 MHz,可以实现AVS高清晰度视频的实时解码。图6为ce(v)解码模块的功能仿真结果图。

本文提出了一种基于AVS标准的熵解码器的硬件结构,从总体设计到各个模块的设计都使用了流水线、并行处理、可重用设计等硬件设计的思想和方法;采用Verilog硬件描述语言实现,并通过FPGA进行了验证,达到了标准清晰度实时解码的要求。
参考文献
[1] 王忠平.AVS和H.264双模解码器SoC混成架构的设计与研究[D].上海:上海交通大学,2008.
[2] AVS联合工作组.信息技术:先进音视频编码第2部分:视频. 2006.
[3] 徐龙,邓磊.AVS熵解码器的VLSI设计[J].计算机研究与发展,2009.
[4] 张楚.AVS和H.264双标准可变长解码器设计[D].西安: 西北工业大学,2007.