
服务机器人以服务为目的,因此人们需要一种更方便、更自然、更加人性化的方式与机器人交互,而不再满足于复杂的键盘和按钮操作。基于听觉的人机交互是该领域的一个重要发展方向。目前主流的语音识别技术是基于统计模式。然而,由于统计模型训练算法复杂,运算量大,一般由工控机、PC机或笔记本来完成,这无疑限制了它的运用。嵌入式语音交互已成为目前研究的热门课题。
嵌入式语音识别系统和PC机的语音识别系统相比,虽然其运算速度和内存容量有一定限制,但它具有体积小、功耗低、可靠性高、投入小、安装灵活等优点,特别适用于智能家居、机器人及消费电子等领域。
1 模块整体方案及架构
语音识别的基本原理如图1所示。语音识别包括两个阶段:训练和识别。不管是训练还是识别,都必须对输入语音预处理和特征提取。训练阶段所做的具体工作是通过用户输入若干次训练语音,经过预处理和特征提取后得到特征矢量参数,最后通过特征建模达到建立训练语音的参考模型库的目的。而识别阶段所做的主要工作是将输入语音的特征矢量参数和参考模型库中的参考模型进行相似性度量比较,然后把相似性最高的输入特征矢量作为识别结果输出。这样,最终就达到了语音识别的目的。
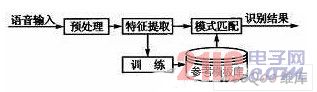
图1 语音识别的基本原理
现有的语音识别技术按照识别对象可以分为特定人识别和非特定人识别。特定人识别是指识别对象为专门的人,非特定人识别是指识别对象是针对大多数用户,一般需要采集多个人的语音进行录音和训练,经过学习,达到较高的识别率。
基于现有技术开发嵌入式语音交互系统,目前主要有两种方式:一种是直接在嵌入式处理器中调用语音开发包;另一种是嵌入式处理器外围扩展语音芯片。第一种方法程序量大,计算复杂,需要占用大量的处理器资源,开发周期长;第二种方法相对简单,只需要关注语音芯片的接口部分与微处理器相连,结构简单,搭建方便,微处理器的计算负担大大降低,增强了可靠性,缩短了开发周期。
语音识别技术在国内外的发展十分迅速。目前国内在PC应用领域,具有代表性的有:科大讯飞的InterReco2.0、中科模式识别的Pattek ASR3.0、捷通华声的jASRv5.5;在嵌入式应用领域,具有代表性的有:凌阳的SPCE061A、ICRoute的LD332X、上海华镇电子的WS-117。
本文的语音识别方案是以嵌入式微处理器为核心,外围加非特定人语音识别芯片及相关电路构成。语音识别芯片选用ICRoute公司的LD33 20芯片。
2 硬件电路设计
如图2所示,硬件电路主要包括主控核心部分和语音识别部分。语音进入语音识别部分后,将处理过的数据并行传输到主控制器,主控制器经过处理后,发送命令数据到USART,USART可用于扩展外围串行设备,如语音合成模块等。

图2 硬件电路
2.1 语音识别电路
图3为语音识别部分原理图,参照了ICRoute发布的LD3320数据手册进行设计。LD3320的内部集成了快速稳定的优化算法,不需外接Fla-sh、RAM,不需要用户事先训练和录音而完成非特定人语音识别,识别准确率高。

图3 语音识别部分原理图
图中,LD3320采用并行方式直接与STM32F103C8T6相接,均采用1kΩ电阻上拉,A0用于判断是数据段还是地址段;控制信号 ,复位信号
,复位信号 以及中断返回信号INTB与STM32F103C8T6直接相连,采用10kΩ电阻上拉,辅助系统稳定工作;和STM32F103C8T6采用同一个外部8 MHz时钟;发光二极管D1、D2用于复位后的上电指示;MBS(引脚12)作为*偏置,接了一个RC电路,保证能输出一个浮动电压给*。
以及中断返回信号INTB与STM32F103C8T6直接相连,采用10kΩ电阻上拉,辅助系统稳定工作;和STM32F103C8T6采用同一个外部8 MHz时钟;发光二极管D1、D2用于复位后的上电指示;MBS(引脚12)作为*偏置,接了一个RC电路,保证能输出一个浮动电压给*。
2.2主控制器电路
本文的主控制器选用的是ST公司的STM32F103C8T6芯片。该芯片基于ARM Cortex-M3 32位的RISC内核,工作频率最高可达72 MHz,内置高速存储器(64 KB的闪存和20 KB的SRAM),丰富的增强I/O端口和联接到两条APB总线的外设。STM32系列提供了全新的32位产品选项,结合了高性能、实时、低功耗、低电压等特性,同时保持了高集成度和易于开发的优势,将32位MCU世界的性能和功效引向一个新的级别。
3 软件系统设计
软件系统的设计主要包括3部分:主控单元的嵌入式操作系统μC/OS-II移植、LD3320的语音识别程序设计、对话管理单元的设计。
3.1 嵌入式操作系统μC/OS-II移植
μC/OS-II是一个源码公开、可移植、可固化、可裁剪、占先式的实时多任务操作系统。它是专门为计算机的嵌入式应用设计的,绝大部分代码采用C语言编写,具有执行效率高、占用空间小、实时性能优良和可扩展性强等特点,最小内核可至2 KB。在μC/OS-II中,任务的概念尤为重要,它是可剥夺型的内核,因此任务优先级的划分至关紧要。基于分层化和模块化的设计理念,整个系统任务的划分如表1所列。
表1 主控系统任务优先级规划

表1中除OSTaskStat和OSTaskIdle任务为系统自带,其他7个任务均为用户创建。App_TaskStart是系统的第一个任务,对系统时钟和底层设备进行初始化,创建所有事件和其他各项用户任务,并对系统状态进行监测;App_TaskSR完成语音识别;App_TaskCmd完成对话集中命令的解析和执行,并通过USART1向外发送;App_TaskCom作为外围扩展任务,通过USART2向外发送指令或数据,负责控制外围扩展设备,如语音合成设备等;
App_TaskUpdate通过解析USART1接收的命令和数据进行对话集的更新;App_TaskPB是按键扫描任务,负责检测3个独立按键,分为短按和长按检测;App_TaskLED驱动4个LED指示灯,指示当前工作状态。
3.2 语音识别程序设计
语音识别程序的设计,参考了LD332X开发手册,本文中采用中断方式工作,其工作流程分为通用初始化一语音识别用初始化-写入识别列表-开始识别-响应中断。
①通用初始化和语音识别用初始化。在初始化程序里,主要完成软复位、模式设定、时钟频率设定、FIFO设定。
②写入识别列表。列表的规则是,每个识别条目对应一个特定的编号(1个字节),编号可以相同,可以不连续,但是数值要小于256(00H~FFH)。本芯片最多支持50个识别条目,每个识别条目是标准普通话的汉语拼音(小写),每2个字(汉语拼音)之间用一个空格间隔。本文中采取了连续不同编号的识别条目,表2是简单的示例。
表2 识别列表示例

③开始识别。设置几个相关的寄存器,即可开始语音的识别。图4是相关的流程。ADC通道即为*输入通道,ADC增益也就是*音量,可设定值00H~7FH,建议设置值为40H~6FH,值越大代表MIC音量越大,识别启动越敏感,但可能带来更多误识别;值越小代表MIC音量越小,需要近距离说话才能启动识别功能,好处是对远处的干扰语音没有反应。本文中设定值为43H。

图4 开始识别流程
④响应中断。如果*采集到声音,不管是否识别出正常结果,都会产生一个中断信号。而中断程序要根据寄存器的值分析结果。读取BA寄存器的值,可以知道有几个候选答案,而C5寄存器里的答案是得分最高、最可能正确的答案。
3.3 对话管理单元设计
为了方便进行对话的管理,本文中设计了一个对话管理单元,用于对等待识别的语句和等待执行的命令进行存储,在主控制器中通过定义二维数组来实现。LD3320每次识别最多可以设置50项候选识别句,每个识别句可以是单字、词组或短句,长度为不超过10个汉字或者79个字节的拼音串。基于上述原因,本文设计的对话管理数组如表3所列。
表3 对话管理单元数组

行为数组中存储要执行的行为编号,对应于50条语音识别语句,共有50组指令,每组指令中可以最多包含6个行为,并行的行为可以归为一步,通过多个行为的组合,就可以完成更复杂的任务。
4 性能测试与应用
为了保证设计的语音识别模块的语音识别率、稳定性和响应时间,本文对所描述的语音识别模块做了相应的测试,测试环境分别为安静的家庭环境和嘈杂的医院环境,共8条语音指令,对每条语音指令分别进行10次测试,每个环境下对每个特定人的总实验次数为80次,记录成功识别的次数。测试结果如表4所列。
表4 测试结果

测试中的3个非特定人中,非特定人1为女性,非特定人2和非特定人3为男性。由表中数据可以看出,家庭环境下对非特定人的语音识别率可达到90%以上,嘈杂的医院环境下的语音识别率也可达82.5%以上。识别率方面,在嘈杂环境下比在安静环境下的语音识别率有所降低;稳定性方面,在安静环境下系统的稳定性较好,语音说1遍,最多说2遍模块就可以做出正确的响应;在噪声环境下,系统的稳定性有所下降,个别语音命令需要说3遍甚至3遍以上才能被模块准确识别;实时性方面,在安静环境下的语音能保证系统响应的实时性,响应时间一般不超过1 s,在噪声环境下的响应时间相对长一些。
结语
本文讨论了基于STM32的嵌入式语音识别模块的设计和实现,对模块各个组成单元的硬件电路及软件实现进行了详细的介绍。大量实验及实际应用表明,本文设计的语音识别模块具有稳定性好、语音识别率高、抗噪声干扰能力强、结构简单和使用方便等特点。该模块实用性强,可广泛应用于服务机器人智能空间、智能家居和消费电子产品等多个领域。