
应用IA MMXTM技术的离散余弦变换
2009-02-03
作者:李维钊 王广伟
摘 要: 在简要介绍IA(Intel Architecture) MMXTM技术的基础上,重点讨论了应用IA MMXTM技术的DCT快速算法及其优越性能。
关键词: Intel体系结构 IA MMXTM技术 快速算法 离散余弦变换(DCT)和离散余弦反变换(IDCT)
1 IA MMXTM技术简介
个人计算机处理数据的复杂度和数量的急剧增长,对微处理器的性能提出了更高的要求。其中以视频、3D图形、动画、音频和虚拟现实为特征的应用更是对微处理器的性能提出崭新的要求。IA MMXTM技术应运而生。它的设计目的就是用来加强多媒体和通信方面的应用。这一技术包括新的指令和数据类型。IA MMXTM技术介绍了一些新的通用指令,这些指令以并行处理的方式完成对一个64位数据组中的多个数据元素的操作。IA MMXTM指令集在不增加新的模式并保持对操作系统的透明性的基础上,形成了一个简单而灵活的软件模型。IA MMXTM技术定义了57条新的指令、8个64位宽度的IA MMXTM 寄存器和四种新数据类型。
IA MMXTM 技术最重要的特点是单指令多操作数据(SIMD),这一技术允许一条指令并行处理多个数据元素。正是这种并行处理的能力极大地提高了应用程序的性能。IA MMXTM指令处理定点数,多个整数字节、字或双字被组合在一个单独的64位IA MMXTM寄存器中。定点值的小数点位置由程序员自己决定,这样保证了处理数据精度的灵活性。在IA MMXTM技术中支持有符号和无符号的定点整数字节、字、双字和四字的各种运算。
Intel Pentium处理器是先进的超标量处理器,它建立在两个通用整数流水线和一个可流水作业的浮点处理单元之上。一个软件透明的动态分支预测机制使得流水线阻塞降低到最小。带有IA MMXTM 技术的Intel Pentium处理器给流水线加入新的处理阶段。Intel Pentium处理器能在一个时钟周期内执行两条指令,每条流水线执行一条指令。第一条逻辑流水线称为U流水线,第二条称为V流水线。在任何指令的解码期间,下两条指令被检查,如果可能,它们被分别送入U、V流水线;否则,下一条指令送入U流水线,而没有指令送入V流水线。IA MMXTM技术指令通过指令调度可以充分利用Intel Pentium处理器的双流水线机制以提高程序的运行速度。IA MMXTM 寄存器和状态是IA浮点寄存器和状态的别名,这保证了IA MMXTM技术与现有的操作系统和应用的完全兼容性。但是应用浮点操作和IA MMXTM指令混合编程时,浮点操作指令流和IA MMXTM指令流必须分开并且在执行完离开时要进行必要的清理工作,在IA MMXTM技术指令后要写一条EMMS指令,在浮点操作完成后要清空浮点寄存器堆栈。IA MMXTM技术指令集如表1所示。

由于IA 体系的复杂性和IA MMXTM技术的本身特点,开发一个应用IA MMXTM技术的应用程序将是比较复杂的,涉及到许多方面。其中主要有应用的特点是否适应IA MMXTM技术的要求,算法是否具有强的并行特点。这是决定应用IA MMXTM技术的前提条件。具体在编程时要进行优化,一般的优化策略包括地址生成互锁(AGI)优化、代码及数据对齐、避免部分寄存器阻塞、分支预测信息和指令的合理调度。另外指令选择优化、内存优化和高速缓存优化也极大地制约了应用的性能。
2 图象处理中的DCT和IDCT
在图象处理中,离散余弦变换(DCT)及其反变换(IDCT)一直是运动估计/补偿变换编解码系统的速度瓶颈。尽管出现了大量的快速算法,但是由于图象处理数据量非常大,使得这一系统在实时应用中性能不佳。注意到图象处理的DCT中,输入数据和输出数据都是整数,基于这一特点本文介绍了应用奔腾处理器IA MMXTM技术,选择特定的快速算法,将8×8块的DCT和IDCT的速度提高了3倍以上。限于篇幅,这里只介绍DCT。
2.1采用行列快速算法DCT
在计算二维N×N点DCT时、一种常用的算法是采用行列快速算法。该算法首先按行计算N个一维DCT,再按列计算N个一维DCT,从而把乘法的计算量减少到直接计算的一半,其算法规律性强,便于程序实现。
c(u)=α(u)∑f(n)cos[πu(2n+1)/2N] (1)
(1)式给出了计算公式、这里、α(0)=1/![]() 、 α(u)=
、 α(u)=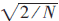 ,u≠0。直接计算一个1D N点DCT的乘法次数为N2次。通过研究DCT的特点,Chun-Yen Lu和Kuei-Ann Wen提出了系数选择8点一维DCT模式,现在简单介绍其方法。实数序列{f(n):n=0、1、...、N-1}的1D DCT-II可以表述如下:
,u≠0。直接计算一个1D N点DCT的乘法次数为N2次。通过研究DCT的特点,Chun-Yen Lu和Kuei-Ann Wen提出了系数选择8点一维DCT模式,现在简单介绍其方法。实数序列{f(n):n=0、1、...、N-1}的1D DCT-II可以表述如下:
在这里我们设定N=8、对于(1)式我们定义如下的系数矩阵F(n)和数据矩阵D(n):


从(2)式可以看出,1D8点DCT的计算可以分解为以下几步:
·计算数据向量D;
·通过排列矩阵P重新排列D0,D1,D2和D3,即:D’=PD;
·计算SFD’,相应的余弦系数集通过选择矩阵Si从F中选择。
通过这一过程,我们不难看出,系数选择模式1D 8点DCT具有简明的规律性,便于程序实现。
2.2 算法的IA MMXTM技术实现
2.2.1 对上述算法的改进
简单地利用(2)式来计算DCT,并不能充分发挥IA MMXTM技术的优越性能,我们对(2)式做如下变形:

u=0、1...7。[D′(u)]T是8点数据的规律性组合(见D(u)、区别是分别去掉了系数1、p(n)、q(n)、r(n)),是DCT的固定部分,对于不同数据的DCT保持不变。 从而将DCT分为固定部分[[SuF] [PuDc(u)]]T,和数据部分D′(u)。这样计算时可以首先计算[[SuF][PuDc(u)]]T并制成表存储起来,程序中通过查表获取乘法因子。从而使得1D8点DCT的计算变得适合IA MMXTM技术的实现。
2.2.2 将浮点运算转换为整数运算
虽然通过算法的改进使之适合程序实现、但是在算法中仍然存在浮点乘法、对于数字视频,其象素的各个分量一般为8位整数,为了消除浮点运算,将余弦系数扩大65536倍,相当于左移16位,因为这里的余弦系数都小于1/2,因此扩大后的数据不会超出16位有符号短整型数据的范围。这样就把浮点运算转化为整型运算。制定如下数组:
short A[8][4]={{iA1、iA1、iA1、iA1}、{iC1、iC2、iC3、iC4}、{iB1、iB2、-iB2、-iB1}、{iC2、-iC4、-iC1、-iC3}、{iA1、-iA1、-iA1、iA1}、{iC3、-iC1、iC4、iC2}、{iB2、-iB1、iB1、-iB2}、{iC4、-iC3、iC2、-iC1}};
其中iA1=A1×65536,iBu=Bu×65536,iCj=Cj×65536,u=1,2;j=1,2,3,4。注意到该数组共占用8×4×2=64个字节,正好是奔腾处理器高速缓存线的整数倍,并且要把数组的起始位置放在32字节边界上,这样就可以优化高速缓存的线读入。
2.2.3 输入数据格式
假设输入是按自然顺序的8点数据,由D(n)的定义、在处理前要对后四点进行反序调整、既将前四点按顺序放入MMXTM寄存器中、并将其扩展成16位数据、将后四位反序后以同样的格式放入另一个MMXTM寄存器中。这样可以用以下三条指令得出f(i)±f(7-i)、i=0、1、2、3。(设前四个放在MM0中、后四个放在MM2中)。
MOVQ MM1、MM0
PADDSW MM0、MM2 //MM0存放四个和值
PSUBSW MM1、MM2 //MM1存放四个差值
这样、MM0和MM1为分别对应n为偶数和奇数的情况。调整好输入数据的格式将为IA MMXTM技术指令的应用提供极大方便。
2.2.4 乘法运算与精度问题
通过以上的准备工作,接下来就是依次计算8个DCT系数C(u)(u=0、1...7)了。这涉及到指令选择的优化问题,从公式(3)我们知道,对于每个DCT系数C(u)是四个并行16位×16位的整数乘积的和,为了保证精度要求结果保留32位。在IA MMXTM技术指令集中,PMADDWD 正好完成这一并行乘法运算和两个乘积的和值计算,只要再做一次和就可以得出结果。另外,要根据n是偶数或奇数选择f(i)±f(7-i)。下面是PMADDWD的操作示例:

在做完乘法和加法以后,要对数据进行右移16位,相当于除以65536,这样就将数据还原为其真实值了。如果要进一步提高精度可以对数据进行四舍五入处理,关于这一点在此不做详细说明。鉴于程序流程简单明了,其流程图和程序清单就不在此占用篇幅了。
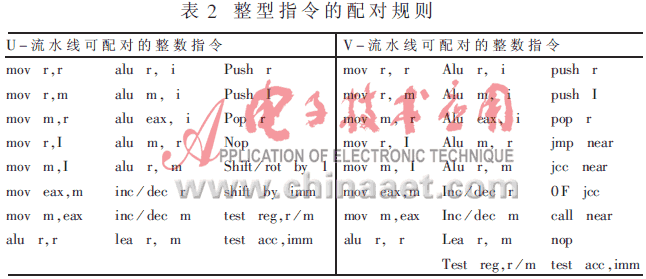
在实际编程中,必须注意指令的调度问题,这也是程序优化的很关键的一个方面。下面就IA MMXTM技术指令与整型指令的配对规则做简要介绍。
· 整型指令的配对规则如表2
· MMXTM技术指令的配对
(1)由于仅有一个MMXTM移位单元,所以两条MMXTM移位单元的MMXTM指令不能配对。移位操作可以在U流水线或V流水线中进行,但不能在同一个时钟周期内的两个流水线中处理。
(2) 同样,两条MMXTM乘法指令不能配对。
(3) 无论是对内存还是对整数寄存器的文件访问的MMXTM指令仅被U流水线处理。
(4) U流水线指令的MMXTM目的寄存器不与V流水线指令的源或目的寄存器配对。
(5) EMMS指令不可配对。
· U流水线中的整数指令和V流水线中的MMXTM技术指令配对规则
(1)在浮点指令之后的第一条指令不能是MMXTM技术指令。
(2)V流水线的MMXTM指令不能访问内存或整数寄存器文件。
(3)U流水线整数指令是可配对的U流水线整数指令。
· U流水线中的MMXTM技术指令和V流水线中的整数指令配对规则
(1)V流水线整数指令是可配对的V流水线整数指令。
(2)U流水线MMXTM指令不能对内存或整数寄存器存取。
根据以上配对原则,相信读者可以自己安排程序中的指令配对。
该程序虽然占用了不多的存储单元,但是(接上页)
却极大地提高了运算速度,由于大存储量的存储体价格较低,因此这一点并不重要。
除此之外,笔者还在运动估计搜索算法中应用IA MMXTM技术,同样性能显著地提高了。
总之,IA MMXTM技术在数据处理的许多算法中都能发挥优越的性能,能够成倍地提高运行速度。目前在多媒体应用中,离散余弦变换(DCT)是经常用到的变换编码技术,因此提高DCT的速度一直是这一应用领域中的关键。利用IA MMXTM技术在不增加其他硬件的情况下,充分发挥Intel Pentium处理器的性能可以轻松地完成这一任务。在多媒体应用中,IA MMXTM技术大大降低了程序对处理器的占用率,使处理器能够同时更有效地执行其他任务。
参考文献
1 Intel Architecture MMXTM Technology Programmer's Reference Manual.1996
2 Intel Architecture MMXTM Technology Manual.1996.
3 [美]Intel公司著,李晖译.Intel体系结构MMXTM技术开发指南.北京:电子工业出版社,1997
4 Chung-Yen Lu,Kuei-Ann Wen.On the Design of Selective Coefficient DCT Module.IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY、1998;8(2)(收稿日期:1999-12-29)