
0 引言
在大规模高性能的ASIC设计中,对时钟偏移(Clock Skew)的要求越来越严格,时钟偏移是限制系统时钟频率的主要因素。而时钟树综合又是减小时钟偏移的有效途径,因此它是ASIC后端设计中最重要的环节之一。本文以基于SOC Encounter,采用SMIC0.18μm工艺进行的FFT处理器的版图设计为例,提出在设计过程中如何减小时钟偏移,结合手动优化帮助工具设计出更好的时钟树。
1 时钟偏移产生的原因分析
同一时钟源到达各个同步单元的最大时间差称作时钟偏移。产生时钟偏移的原因有:时钟源到各个时钟端点的路径长度不同;各个端点负载不同;在时钟网中插入的缓冲器不同等。时钟偏差过大会引起同步电路功能混乱。
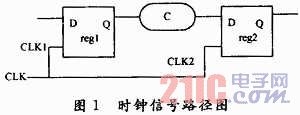
在图1中,假设CLK到达reg1和reg2的时间差最大,为dskew,组合逻辑C的延时为dc,寄存器的延时为d,其建立时间约束为dsetup,保持时间为dhold,时钟周期为T。满足建立时间的要求是在CLK2跳变前的dsetup时间,reg2上D端的数据应该稳定,考虑最坏情况reg1比reg2晚dskew,这时满足的时间关系应该是:
![]()
满足保持时间的要求是:在CLK2跳变后的dhold时间内,reg2上D端的数据必须保持稳定,考虑最坏情况reg1比reg2早dskew,这时满足的时间关系应该是:
![]()
由此可见,时钟偏移对电路速度和时钟频率的限制是很大的,而寄存器的保持时间、建立时间和自身的延时,都是与器件单元本身的结构和性质有关,依赖于工艺的改进来进一步减小,所以减小skew成为后端设计重要内容,也是提高电路速度的关键。
2 SOC Encounter的时钟树综合
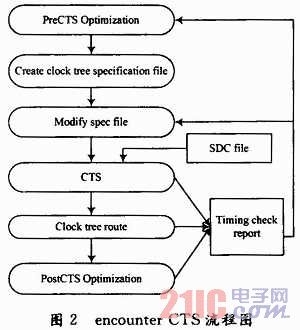
SOC Encounter的时钟树综合在完成布局之后进行,可以采用手动模式和自动模式。手动模式能控制时钟树的层次、buffer的数目和每层加入buffer的类型。自动模式根据时钟树定义文件自动决定时钟树的层次和buffer的数目。时钟树综合从外部时钟输入端口自动遍历整个时钟树,遍历完成后加入buffer用来平衡时钟树。SOC Encounter的时钟树综合流程如图2所示。
2.1 布局阶段对时序的优化考虑
布局的好坏直接影响到时序的好坏。本设计采用时序驱动布局,时序驱动布局是基于连续收敛引擎而设计的,工具自动的寻找一些最关键路径,将关键路径上的单元放得很近,以减小连线长度来减小关键路径时延,平衡其setup时间约束,预先为这些关键路径留出足够的布线空间,提高关键信号线的可布通性。同时,为了减少拥塞度,对布局时的最大密度设置为70%,限制布局密度。时序驱动布局采用setPlace-Mode-timingDriven命令设置布局模式,plaeeDesign命令执行布局。
如果只是依赖工具的时序驱动布局是不够的,为了尽量减小时钟偏移(Skew),采取的策略是,在时序驱动布局的基础上,进行手动的布局调整,根据时钟的不同,将各时钟控制的寄存器摆在靠近时钟源(Clock-source)差不多远的位置。这样,同一时钟到达各寄存器的时间差就不会太大,有利于减少插入buffer的数量,也有利于Skew的减小。
2.2 时钟树综合时的特殊处理
在时钟树综合之前,需要通过时钟树约束文件来设置综合需要用到的buffer类型、时钟偏移的目标值MaxSkew、最大时延MaxDelay、最小时延MinDelay、最大扇出MaxFanout、时钟树布线规则等。本设计选用驱动能力为中间值的buffer类型来做时钟树综合,因为驱动能力大的buffer,面积也大,如果插入这种buffer太多,会对芯片的功耗和面积产生影响,而且这种buffer对于上一级也意味着更大的负载;驱动能力太小的buffer虽然面积小点,但是会增加时钟级数,产生的延时却是很大的,所以buffer的选择一定要适当,本设计在选用buffer时,将驱动能力最大的BUFHD20X和驱动能力最小的BUFHDLX去掉不选用。
对于Skew要求比较严格的设计,可以将时钟偏移目标值MaxSkew设置尽量小,工具在综合时会尽量的将Skew优化到接近到该目标值。但一般设计中,只要Skew能满足要求,就不要过分的将该值设小,因为工具为了接近该目标值会插入大量的buffer,从而占用太多的面积和太多功耗。因此,本设计选用MaxSkew的适当值为100ps。
时钟树布线规则是可以通过手动设置的,为了让时序路径的布线降低功耗,减小线路的延时,一般将时序路径的布线宽度和间距都设置的比默认值大,本设计采取一般信号线的两倍宽度和间距来布时钟信号线。而且在布线的时候,采取时钟树优先布线的策略,充分保证时钟树路径的布通。经过encounter工具自动CTS后的时钟树分布图如图3所示。

2.3 时钟树的手动优化
工具自动的时钟树综合总是会有一些skew没有满足设计要求,工具自动插入的一些buffer也不一定都合理,一般情况下,encounter自动综合产生的时钟树是不满足要求的,在经过了时序分析后要进行必要的修复优化。总的原则就是想办法平衡各线路的延时,一般的优化途径有以下一些:
(1)在时钟信号源(Clock Source)处手动添加驱动能力很大的drive cell,因为时钟树一般扇出很大,负载很大,所以在时钟源点处需要驱动能力大的门单元,更大驱动能力的门单元可以明显减少延时。
(2)替换(Re_sizing)驱动能力不一样的单元,尤其是buffer单元。时钟树综合完成后,经过仔细的时序分析后,根据时序分析结果报告,分析Skew违规原因,找出导致Skew违规的路径,根据延时情况来替换一些驱动能力不同的单元,如buffer等,使其延时情况与其他时钟信号线相平衡,从而达到减小Skew的目的。
(3)添加buffer。互连线的延时与连线长度的平方成正比,所以插入buffer可以将长的关键路径分成较小的连线,可以有效地减小互连线的延时。插入的buffer的驱动能力的大小靠经验估计,插入后做时序分析,然后再做re_sizing,直到满足延时要求。
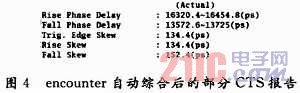
经过eneounter自动时钟树综合后,查看其CTS时序报告,如图4所示,发现时钟elk_pad的最大偏移值达到了152.4 ps,这样与目标值还有很大差距。经过timing Debug跟踪时钟信号,如图5所示,从中找出一些Skew较大的线路,如从fft4442_inst/CT/M3_R_reg/Q到fft4442 _inst/PEII/pc42_in4_reg_76_/RN的延时太长,达到了27.035 ns,因为这样的线路与其他信号线的延时相差比较大,它们之间的Skew就很容易违规,必须减小它们的延时来减小Skew。
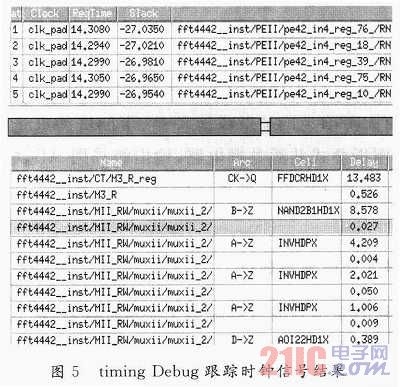
再进一步查看该线路,发现有些单元,如FFDCRHD1X延时达到13.483 ns,HAND281HD1X延时达到8.578ns,INVHDPX也达到了4.209ns,而且该线路还插入了不少BUFHD1X,由于此类buffer的驱动能力太小,从而导致了该线路的延时过大。于是,采用第二类修复办法:替换(r-e_sizing)驱动能力不一样的buffer。于是调用Interactive ECO功能,手动将延时太长的单元FFDCRHD1X、HAND2B1HD1X等的尺寸替换为更大的,从而加强其驱动能力,并将部分BUFHD1X替换成BUFHD4X等,再做了PostCTS optimization后,再进行时序分析,这样经过几轮反复的修复,降低了一些线路的延时,终于将时钟CLK的Skew降到了93.3ps,如图6所示,满足了设计要求。从eneounter的CTS报告中可以看出,加上有针对性的手动修复之后,对Skew的减小有明显效果。

3 结语
随着集成电路设计尺寸的减小和芯片运行频率的提高,时钟偏移已经成为影响ASIC芯片性能的关键因素。本文以对FFT处理器芯片的时钟树综合为例,分析了时钟偏移的产生机理及影响,从布局阶段就开始关注时序的优化,进行了一系列的优化设置。经过时序分析证明,采取工具自动综合和手动修复相结合的办法,容易满足设计要求,不仅可以提高综合效率,还可以保证优化的有效性。