
摘 要: 提出了在title="TMS320C5416">TMS320C5416 DSP硬件开发平台上实时实现G.723.1的解决方案。根据G.723.1标准实时实现的要求对程序进行了优化,最终在TMS320C5416 DSP上实时实现了该标准。语音质量良好,达到了通信质量的要求。
关键词: 语音编码;ITU-T G.723.1协议;ACELP;MPE_LPC;DSP芯片;算法优化
随着通信、计算机网络等技术的飞速发展,日益增加的客户需求量和现有的通信信道容量之间的矛盾愈发突出。如何在有限的信道资源下,通过压缩信源以提高传输效率已成为当前急需解决的问题之一。为此诞生了许多语音压缩处理方法,G.723.1语音编码算法便是ITU-T(国际电信联盟电信标准化部门)制定的H.324协议簇首推的标准算法,主要用于低比特率多媒体业务的话音或其他音频信号分量的压缩。它是一种双速率语音编码标准,其中6.3 kb/s的速率提供了良好的话音质量,而5.3 kb/s的速率在提供较好通话质量的同时,也为系统设计者提供了更适合的灵活性[1]。
1 算法原理
G.723.1语音编码算法按帧(Frame)对语音数据进行压缩和解压缩,每帧240个采样点,压缩传递的参数包括线性预测系数、自适应码本的延时和增益、激励脉冲位置、符号及格点比特等。
首先进行高通滤波,去掉直流分量;接着把一帧信号分成4个子帧,每个子帧60个采样点,分别进行10阶线性预测分析(LPC),得到各子帧的LPC参数,把最后一个子帧的LPC参数转化成线谱对(LSP)参数进行矢量量化编码,送到解码器。利用未量化的LPC参数构造短时感知加权滤波器,信号滤波后得到感觉加权的语音信号。每2个子帧(120样点)搜索一个开环基音值,并以此为依据为每一个子帧构造一个谐波噪声成形滤波器,对感知加权的语音信号进行滤波。每一子帧的LPC综合滤波器、感觉加权滤波器和谐波噪声成形滤波器联起来,构成一个联合滤波器,利用它的冲激响应和开环基音周期,对每一子帧进行闭环基音搜索,对开环搜索的结果进行修正。同时通过一个五阶基音预测器对信号进行预测,得到相应子帧的残差信号。最后进行固定码本搜索,也就是对每一子帧的残差信号进行矢量量化,对应两种不同的编码速率采用两种不同的方法:编码速率为6.3kb/s时,采用多脉冲最大似然量化(MP-MLQ)的方法,具有较高的重建语音质量;编码速率为5.3kb/d时,采用代数码本激励线性预测(ACELP)方法。
算法的解码也是按帧进行,主要对符合ITU-T G.723.1的码流进行解码,得到相应的参数,根据语音产生的机理,合成语音信号。读入一帧码流后,分别进行LSP参数、基音周期和激励脉冲信号解码,对LSP参数插值,然后转化成各子帧的线性预测系数,构成LPC综合滤波器。通过基音周期和激励脉冲得到每一子帧的残差信号,经过基音后滤波,输入到LPC综合滤波器,产生合成语音信号。经过共振峰后滤波和增益控制,形成高质量的重建语音信号。
2 算法实现
2.1 硬件设计
在选择DSP芯片时,考虑了语音压缩编码算法的复杂度以及运算量,并对DPS芯片本身的运算能力、存储空间大小、性能价格比、开发软件的完整性等多方面进行综合比较,最终选用TIC54xx系列的定点运算处理器TMS320C5416,开发平台是TMS320C5416 DSK。
TMS320C5416的单指令周期为6.25 ms,每秒执行的指令数为160M,使用了6级指令流水线结构,这些都很适合G.723.1语音编码算法的实现。采用一个40 bit ALU、128K×16 bit片内RAM(包括64 kB的片内DARAM和64 KB的片内SARAM)、3个独立的16 bit数据内存总线、1个程序内存总线、3个McBSP、6信道DMA控制器、1个8/16 bit并行增强主机端口接口及2个16 bit计时器[2,3]。
在DSK的基础上,可以搭建出语音开发硬件系统平台,如图1所示。
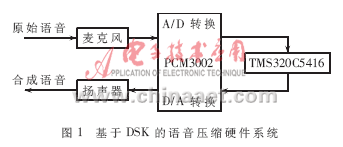
输入语音信号由麦克风输入,经过立体声音频多媒体数字信号编码芯片PCM3002 A/D转换后成为数字信号,接着送入DSP内进行编码压缩处理。处理后的数据经过解压得到重建的语音信号,最后送入PCM3002 D/A转换为模拟信号,通过耳机或扬声器得以收听到。
2.2 算法实现流程
根据G.723.1算法,设计实现流程如图2所示。
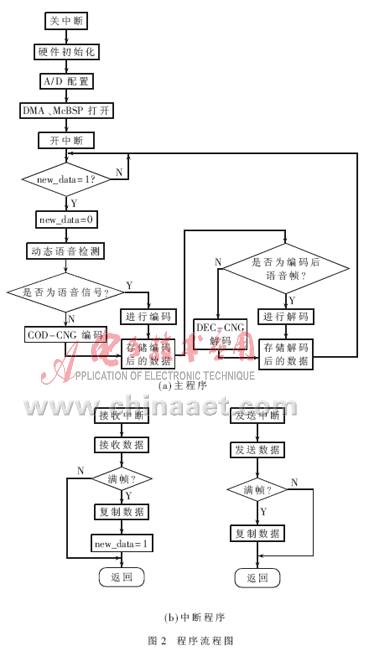
从流程图中可以看到,首先关闭中断、初始化DSP芯片和开发平台;然后进行程序运行前的硬件配置,主要是配置外设,打开DMA和McBSP。配置结束后打开中断屏蔽控制寄存器,等待中断的到来。McBSP接收中断发生时,DMA接收PCM3002发来的数据并存入缓冲区,并判断是否满一帧240个数据。如果不满帧,就直接等待下一次McBSP接收中断;如果满一帧,通过DMA通道3将240个语音数据复制到缓冲区BUFF1,同时置位新帧标志位new_data,然后对数据进行编解码处理。整个编解码结束后,将得到的一帧240个合成语音数据复制到缓冲区BUFF2中,等待新帧标志位重新置1后进行下一帧的编解码处理。McBSP发送中断时,DMA把发送缓冲区的一个数据发送给PCM3002后,判断是否满一帧。如果不满帧,就直接等到下一次McBSP发送中断;如果满一帧,即PCM3002接收到了240个数据,则把BUFF2中新一帧240个合成语音数据复制到发送缓冲区,等待下一次McBSP发送中断。
2.3 DSP/BIOS的配置
将成功实现的算法移植到TI公司提供的TMS320C5416上,采用DSP/BIOS技术编程实现。DSP/BIOS配置工具主要是设置DSP/BIOS各个模块的参数和创建API调用对象[4]。用DSP/BIOS配置工具,对象可以被预先创建和设置,使用这种方法创建静态对象,不仅可以合理利用内存空间、减小代码长度、优化数据结构,还有利于程序编译前通过验证对象的属性预先发现错误。
3 程序优化
实时实现语音信号的编解码最基本的要求是编解一帧语音信号的时间要少于采集一帧语音信号的时间,即要求G.723.1的一帧语音编解码时间要少于30 ms。对G.723.1标准算法进行时间评估时发现,一帧的运算量大概需要49 M个时钟周期,约为300 ms,这显然无法在TMS320C5416 DSP上实时运行。因此有必要从多方面进行优化。
3.1 循环优化
G.723.1实现中的很多运算是在循环内完成的,在循环内部特别是嵌套较深的循环内部,减少一条指令可以大大降低程序的操作次数。固定码本搜索中为了确定四个脉冲的位置和幅度,用到了四重嵌套循环,每重循环8次,在最内层循环减少一条指令,整个程序就减少84=4 096条指令。因此在G.723.1的实现过程中,尽量将内层循环的指令搬移到外层,外层循环的指令搬移到整个循环体外,从而缩短程序执行时间,满足实时性的要求。
此外,适当选择循环指令,如RPT(重复下条指令),RPTZ(累加器清零并重复下条指令)和RPTB(块重复指令)等,也能缩短循环时间。如RPT允许重复执行紧随其后的一条指令,由于要重复的指令只需要取指一次,与利用跳转指令BANZ进行循环相比,效率要高得多。特别是对于乘累加和数据传送多周期指令(MAC、MVDK 和MVPD等),在执行一次之后就变成了单周期指令,大大提高了执行效率。
3.2 使用内联函数
CCS提供的内联函数集中有一些常用的基本运算函数,如加、饱和加、减、饱和减、长数乘等。这些函数可以很方便地被调用,就像调用C函数一样,只要在函数名前加一个“_”,例如_L_SUB(a,b)。这些内联函数是用汇编语句编写的,编译时C编译器将这些内联函数用对应的汇编语句代替,所以执行效率很高。在程序的开始部分头文件中,用#include“intrindefs.h”,代替#include“basic.h”,就是把文件“basic.c”从工程中去掉,从而实现对“basic.c”中许多基本运算函数的优化,提高了执行效率。
3.3 使用宏定义
在G.723.1标准的定点C程序中,所有基本运算都以调用子函数的形式执行。这样做对程序的规范化设计有好处,同时也在很大程度上降低了程序的运算效率。将基本运算由子函数调用改为宏定义可以去掉函数调用的开销,加快运算速度,程序的运算效率明显提高。这种优化方式会带来代码量的增大,但还是在芯片存储空间的容许范围内。
3.4 合理使用流水线操作
C54芯片具有6级深度的流水线,可以完成预取指、取指、译码、产生操作数地址、读取操作数和执行等6个操作,这就出现了指令的重叠。然而CPU总线、寄存器资源是有限的,当不同级别的流水线试图利用同一条总线或访问同一资源时,就可能发生时序上的冲突。如果流水线冲突,CPU自动通过指令延迟的方法解决,有些冲突指令延迟后可以避免,有些则不能避免,需要在指令中间加入NOP空指令才能解决。但这样消耗了额外的时钟周期。重新安排指令顺序有时可以避免冲突,提高程序执行效率,尤其是当NOP指令在循环内部时,可以节省不少的开销。分析程序编译后生成的汇编语言程序,观察分析是否可以进行优化。可以用创建相关图,重新分配运算单元和寄存器、创建排序表重新调整指令顺序等方法去掉NOP指令,同时避免流水线冲突。
3.5 优化效果
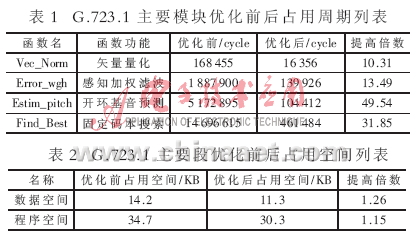
G.723.1语音编解码程序经过优化保证了该算法在DSP中的实时实现。G.723.1协议帧长30 ms,另外有7.5 ms的前瞻,故总帧长为37.5 ms。在硬件仿真模式下对整个程序运行进行测试,结果表明,一帧语音信号的编解码在5.3 kb/s模式下需要3 402 338 clocks,约20.3 ms;在6.3 kb/s模式下需要5 134 901 clocks,约22.83 ms,均低于算法要求的30 ms,在TMS320VC5416上最终完成了G.723.1标准的实时实现。其中各主要模块和主要代码段在优化前后占用周期和空间的对比分别如表1和表2所示。
信噪比是衡量语音编解码质量的客观标准,计算时常用长时信噪比和短时(分段)信噪比两种准则。短时(分段)信噪比采用分段(通常是10 ms~30 ms)的方法来分别计算每一段语音信号的信噪比,因此很适合反映量化器对不同电平输入段的量化质量。本文采用短时(分段)信噪比作为衡量标准。
设每段有N个语音采样点,则第m段的分段信噪比定义为:
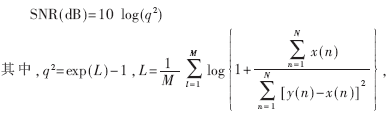
x(n)是原始信号,y(n)是输出信号,N是帧长,M是帧的总数。
本文对G.723.1标准进行测试,就图3所示语音信号计算其短时信噪比。图中总帧数150帧,帧长为240个采样点,按照上式计算SNR=13.56dB。因此可知G.723.1有较高的短时信噪比,语音编解码质量较好,得到的语音信号比较清晰。

参考文献
[1] ITU-T.ITU-T Recommendation G.723.1 dual rate speech coder multimedia communications transmitting at 5.3 and 6.3 Kb/s[S].2006,5.
[2] Texas Instruments.TMS320VC5416 DSK technical reference[R].2002.
[3] Texas Instruments.TMS320VC5416 fixed-point digital signal processor data manual[R].2004.
[4] Texas Instruments.TMS320C54x DSP/BIOS application oro-gramming interface(API) reference guide[R].SPRU404g,2004.
[5] 彭启琮,管庆.DSP集成开发环境-CCS及DSP/BIOS的原理与应用[M].北京:电子工业出版社,2004.
[6] 赵力.语音信号处理[M].北京:机械工业出版社,2003,4.
[7] 韩纪庆.语音信号处理[M].北京:清华大学出版社,2004.
[8] 黄永峰.因特网语音通信技术及其应用[M].北京:人民邮电出版社,2002.