
基于TS101S的IQRD-SMI ADBF多处理器系统
2008-04-11
作者:冯地耘,陈立万,谭进怀
摘 要: 基于多片" title="多片">多片TS101S的并行处理" title="并行处理">并行处理自适应波束形成" title="自适应波束形成">自适应波束形成系统,给出了系统的算法、结构及实验结果。
关键词: TS101S 自适应波束形成 IQRD-SMI 多处理器系统
自适应波束形成是利用现时的输入信号和干扰矢量采用自适应算法进行处理,以达到通过有用信号或需要方向的信号且抑制干扰的目的。由于其可以在恶劣的敌方干扰和电磁兼容环境中提高雷达、通信等系统的抗干扰能力,所以被广泛应用于雷达、声纳和通信等多种军事应用和国民经济领域。当前,自适应波束形成通常采用数字方式在基带实现,即自适应数字波束形成(ADBF)。ADBF与自适应波束形成可视为同一技术。
ADBF技术要完成相当复杂的运算。为了实时实现该技术,一方面要从算法本身提高ADBF系统的处理性能,另一方面需研制处理器结构(特别是以Systolic和Wavefront为代表的高速并行处理机),以满足高速、实时的需要。目前,随着高性能通用DSP的迅猛发展并结合并行性能优越的Systolic阵,采用通用DSP实现自适应波束形成已成为一种趋势。
本文描述了一种基于多片TS101S的并行处理自适应波束形成系统,讨论了系统的算法、结构,给出了实验结果。
1 IQRD-SMI自适应波束形成算法
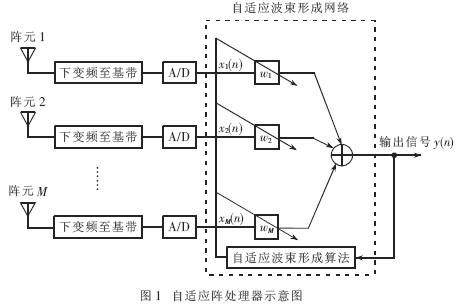
1.1 算法原理
自适应阵处理系统" title="处理系统">处理系统(M阵元的均匀线阵),结构如图1所示。其中中虚线框内为自适应波束形成系统,也是本文研究的部分。设Xn为n次采样得到的n×M维输入数据矩阵,即Xn=[xT(1),xT(2),L,xT(n)]T。其中:xT(i)=[x1(i) x2(i) ∧ xM(i)],i=1,2,……∧ n,表示在第i次快拍时各阵元上的数据。为了提高算法的并行性能,采用数据域ADBF算法,其典型代表是QR分解SMI(QRD-SMI)算法[1~3]。该算法避免了直接利用协方差矩阵Rxx求解线性方程,而是将Rxx分解,并利用Givens旋转实现数据矩阵的QR分解,最终将自适应权矢量w的求解问题转化为如下三角线性方程组的求解问题。
1.2 Systolic阵结构
图2为IQRD-SMI算法的Systolic阵结构(以三阵元为例),所有的并行处理系统可视为以处理器为节点的网络。设计并行处理系统时必须考虑许多问题,其中处理器系统的网络拓扑结构及节点处理器的选择和设计最为重要。良好的专用并行处理系统应该具有模块化、流水处理、局域性等特点。图2所示结构可以很好地满足实时/并行处理的要求。

该Systolic阵包含四种处理器单元。下三角矩阵B(即===)部分的bij单元储存并更新====的各元素;中间向量z(n)中各zi单元用以产生系统进行Givens旋转更新所需的旋转因子;中间向量v中各vi单元完成对vi的储存和更新;最后,wi单元完成权向量的更新和输出。可以看到,该算法及其Systolic阵避免了QR分解SMI算法需要的前后向回代过程,整个Systolic阵系统能高效并行地完成权向量的更新和提取,可以满足实际雷达自适应波束形成系统对实时性的要求。
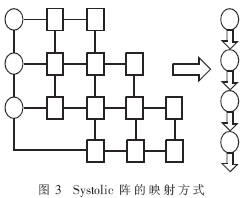
为了减少处理器数目,通常采用线性阵列结构,把实际算法所采用的非线性阵映射为线性阵。本文所采用的映射方式如图3所示。此映射方式有以下优点:处理器单元(PE)数大大减少;数据传递关系简单,数据均从第一个PE节点流入,内部PE节点与外界无输入输出关系,单向流动,在最后一个PE节点以流水方式输出;每一个节点只与相邻的节点有数据交换。该种映射方式能方便地安排输入/输出接口、数据流和控制流,也有利于系统的扩展和重构。
2 多片TS101S实现方案
ADSP-TS101S是ADI公司于2001年底推出的新一代高性能数字信号处理器,主频300MHz,片内存储器6Mbit。它是由ADSP-2106x/2116x系列发展起来的一款极高性能的静态超标量处理器,专为大的信号处理任务和通信结构进行了优化。TS101S静态超标量结构使DSP每周期能够执行多达4条指令、24个16位定点运算和6个浮点运算。其优越的运算处理性能使得采用通用DSP实时地实现ADBF成为可能。
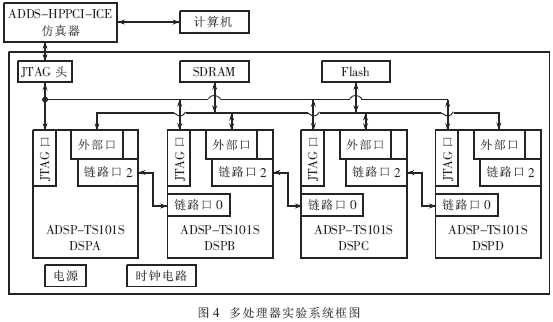
笔者研制的含有4片TS101S的多处理器实验系统如图4。系统为链路口耦合流水线方式多处理器系统,因为TS101S链路口传输数据率与外部总线相当,同时链路口耦合方式具有片间通信简单、能实现无缝连接、各DSP程序可以独立设计、PCB板设计容易等优点。片间数据传送采用链路口链式DMA方式,链式DMA在完成一次DMA传输后,能自动对DMA参数寄存器载入新值,实现自动初始化(无需处理器核干预),开始下一次传输。片间通信采用链式DMA中断方式,中断在整个链序列结束后产生。板上还接一32MB的SDRAM和4Mbit的Flash,它们都挂接在各DSP的外部总线上。四片DSP的JTAG口连在一起通过仿真器与计算机通信,ADBF模拟用的数据、系数因子及DSP程序利用仿真器(系统采用ADI公司的ADDS-HPPCI-ICE仿真器)通过JTAG口下载到各DSP上。处理数据的流向依次为:DSPA→DSPB→DSPC→DSPD,最后在DSPD完成波束形成,在任务分配上应注意各DSP均匀分配。软件平台使用VisualDSP++3.5。
并行处理机的基本性能取决于组成并行处理机的要素:处理单元、并行处理机网络结构、并行算法程序和任务分配方法。实验方案对上述要素均有较好的把握。
3 实验结果
实验模型为:8阵元,均匀线阵(ULA),阵元间距为λ/2。为了测试算法和DSP实现系统方案的性能,按照采样数满足基本数2M(16次)的条件分析系统对单干扰和双干扰的实验性能。当采样数增大时,使得协方差矩阵的估计越充分,干扰抑制深度进一步加深,并且旁瓣性能逐步改善。为了改善波束旁瓣性能,均采用了对角加载" title="加载">加载技术(实验过程未采用操纵矢量加窗)。本文做了大量的实验,实验结果与计算机仿真一致。
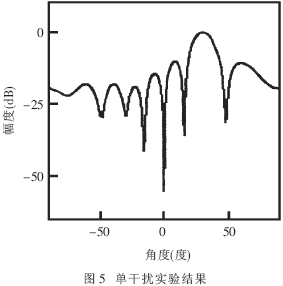
图5为单干扰源实验结果。自适应阵的瞄准方向为30°,信号噪声比(SNR)为20dB;干扰噪声比(INR)为40dB,到来角为0°。30dB加载。可以看到处理系统在干扰方向产生了相当深的零点,其零深约为-60dB。

图6为双干扰源实验结果。自适应阵的瞄准方向为20°,信号噪声比(SNR)为30dB;干扰1:干扰噪声比为80dB(强干扰),到来角为0°;干扰2:干扰噪声比为20dB(弱干扰),到来角为-20°。60dB加载。可以看到处理系统在两个干扰方向均产生了相当深的零点,一个零深约为-70dB(对强干扰),另一个约为-30dB(对弱干扰)。其中对弱干扰的抑制没有强干扰的明显,原因在于对角加载的影响。理论证明:对角加载在改善波束旁瓣性能的同时,对弱干扰的抑制有所降低,在加载时加载值应合理选择。
对于双干扰,实际测得系统的响应时间为10ms。这只是采用四片TS101S并行处理的结果,如果采用更多片TS101S,则响应时间会更短。这对于大多数实际雷达干扰环境来说,可以保证干扰抑制系统的实时性。
为了实时地完成自适应波束形成,必须采用并行性能优越的自适应波束形成算法和高性能的处理器及多处理器并行处理技术。本文给出了一种并行性能较好的数据域自适应波束形成算法——MQRD-SMI算法,研究了算法原理,并重点讨论了其Systolic阵结构及该算法基于多TS101S的并行实现方案,获得了较满意的实验结果。采用更多片以及更高性能的DSP进行并行处理,可获得更高的速度,本文的设计思路仍然适用。
参考文献
1 龚耀寰.自适应滤波——时域自适应滤波和智能天线.北京:电子工业出版社,2003
2 Teitelbaum K.A.Flexible processor for a digital adaptive array radar.IEEE Trans Systems Magazine,May 1991,AES:18~22
3 Rader C M.VLSI Systolic arrays for adaptive nulling.IEEE Singal Processing Magazine,1996
4 Analog Devices Inc.ADSP-TS101 TigerSHARC Processor Hardware Reference.USA,2004
5 刘书明,苏 涛,罗军辉.TigerSHARC DSP 应用系统设计.北京:电子工业出版社,2004