
用XML实现程序中基于浏览器的Web服务
2008-12-20
作者:邱扬
1. 前言
在一些多功能服务系统的开发过程中,我们遇到了这样的问题:作为体系框架的应用程序和基于浏览器和WEB页面的网络服务很难沟通起来。有什么方法能够把这两种传统意义上大相径庭的开发方式高效、稳定地集成,以尽可能地发挥其各自的优势呢?
2. 问题与思考
运行在浏览器上的HTML语言有着高效,灵活的优势,在JAVA程序中,通过内嵌" title="内嵌">内嵌开放式的JAVA浏览器Mozilla,用WEB页面的形式实现一些用户操作界面,能够节约很多开发的精力。但浏览器的编程接口一般限于导航,对网页内部的构件和数据的访问支持不够。当主程序" title="主程序">主程序中采集到的数据参数需要经由HTTP协议提交到数据远程服务器,并由浏览器显示返回的结果页面时,如何将这些参数传递给浏览器的提交页面,同时又使主程序能得到远程返回的数据,便成为了一个需要解决的问题。
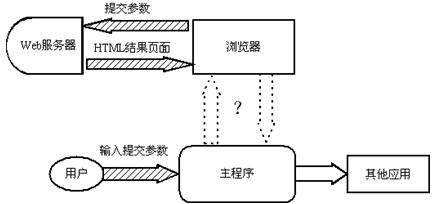
图1. 问题所在——主程序与浏览器页面的数据传递
传统的基于浏览器的Web服务模式是:浏览器与服务器直接建立连接关系,服务器直接返回Web页面。如果尝试打破这种模式,由主程序提交数据,服务器以XML文件的形式返回必要的结果数据,交由程序处理,那么数据共享的问题就得以解决。同时根据预先制定的HTML模板生成本地页面文件,再通过浏览器向用户显示,也能达到与远程页面相同的效果。
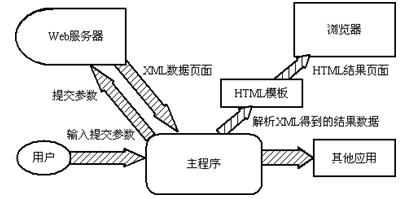
图2. 问题的解决——另一种数据传输模式
3.基本原理
由JAVA实现程序的主框架,内嵌Mozilla的WebClient浏览器组件。发生服务请求时,在程序中利用Http网络对象将参数以Post的方式提交至远程Servlet数据服务器。服务端" title="服务端">服务端处理请求后返回一个包含结果数据的XML页面。客户端" title="客户端">客户端得到XML文件后使用DOM对象解析出结果数据,并根据预先设计的HTML页面模板,通过关键字替换的方式在本地生成结果页面。最后在程序中调用浏览器的SetURL接口指定浏览器打开本地页面。
4.JAVA中的Http请求
Sun的jdk1.3.1中,java.net包提供了一些网络访问功能的对象。其中网络地址对象URL和连接对象HttpURLConnection类用于建立一个远程的Http访问。
下面是它们的一些主要方法及描述。
URL类:

下面是使用这两个对象对网络上的Servlet服务器进行数据查询的例子。
使用查询脚本的地址描述作为参数创建一个URL对象实例,调用URL的openConnection方法打开连接。此时程序试图连接远端并请求脚本服务,如成功即返回一个HttpURLConnection连接实例。
用连接实例的getOutputStream方法取得它的输出流,在输入参数字串" title="字串">字串后,服务器从后台数据库中查询出结果数据,组成XML字符流并输出,客户端由getInputStream得到的输入流取得并保存XML文件。写入参数前可以通过setRequestMethod方法设置提交方法,建议在参数较复杂时使用“POST”方法。根据HTML的协议规范,参数之间用“&”号隔开。
以下是主要程序代码,已通过jdk1.3.1调试。
//指定远程的查询服务脚本地址
URL url = new URL("http://192.168.0.176:7001/WebApp/BasicInfQuery");
//打开Http连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
//提交参数pid和name
PrintWriter out = new PrintWriter(connection.getOutputStream());
String pid = "pid="+URLEncoder.encode(“97133225");
String name = "name="+URLEncoder.encode("yang");
out.println(pid+“&”+name);
out.close();
//读取查询服务返回的数据
BufferedReader in
= new BufferedReader(new InputStreamReader(connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
in.close();
}
5.XML数据结构定义和文件解析
以一个学生信息查询为例,为XML作如下的数据结构定义:以“学生信息”为根,“学生”为节点,每个节点有一个属性“性别”,及“姓名”、“年龄”、“电话”三个子节点。
客户端程序在提交查询后,得到服务端程序动态生成的XML文件,然后利用JAVA下的DOM对象将文件中的数据解析出来。“文档对象模型”DOM是W3C制定的XML数据概念描述,它允许开发者在 XML 结构内引用、检索和更改 XML 结构中的各项。在Sun的jdk1.4.1中包含了XML解析接口javax.xml.parser和DOM对象,它们对XML文件的处理提供了很完整的一套接口。
DOM在处理XML文件之前,首先将XML文件解析成对象化的文档(Document)。javax.xml.parsers中的DocumentBuilder通过parse方法对一个XML文件进行解析,生成一个Document对象。简单要代码如下:
//为解析XML作准备,创建DocumentBuilderFactory实例,指定DocumentBuilder
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
//解析指定的XML文件,创建Document对象
Document doc = db.parse(inFile);
解析后的Document将所有数据以父子的节点层次结构装入内存,这些节点可以是元素、文本、属性或其它节点类型。节点元素对象Element提供了对其元素的值和子节点的访问。下面是Element对象的一些方法定义和描述。
方法 描述
GetAttribute(String name) 取得指定属性名的属性值
GetElementsByTagName(String name) 取得指定节点名的子节点队列
getElementsByTagName 返回的NodeList对象实质是一个Element的队列,其item(n)方法返回其中的第n个Element对象。
以下一段代码用于读取Document对象中树形节点的值:
Element root = doc.getDocumentElement();
//取"学生"元素列表
NodeList students = root.getElementsByTagName("学生");
for (int i = 0; i < students.getLength(); i++)
{
//依次取每个"学生"元素
Element student = (Element) students.item(i);
//取学生的性别属性
String sex = student.getAttribute("性别");
//取"姓名"元素,其他类同
NodeList names = student.getElementsByTagName("姓名");
if (names.getLength() == 1) {
Element e = (Element) names.item(0);
Text t = (Text) e.getFirstChild();
String name = t.getNodeValue();
}
}
注:在Apache提供的XML开发工具包crimson的帮助下,DOM对象也能用于将一个Document的数据写入XML文件。在我们的数据服务器端,因为生成XML文件相比较解析文件来的简单,我们并没有使用这一功能,但在一些XML结构较复杂的情况下,使用一个清晰的文档对象也是很有必要的。相关的资料可参考Apache网站上crimson的开发文档。
6.HTML模板定义和页面的动态创建
HTML模板是在源码中添加了一些自定义的标记(tag)的HTML文件,这些tag用于在动态创建页面时指示数据字串的插入位置。
对于预先设计的HTML页面,以文本方式编辑他们的源码。在显示数据的位置用自定义的tag作出标记,这些tag以一个在HTML语法中不常出现的特殊符号作为起始和终止符,如”%”,以它们的数据意义来命名。例如姓名的tag定义为”%name%”,性别为”%sex%”,类似。下面是一个模板中部分代码的举例:
姓名 %name%
性别 %sex%
年龄 %age%
在创建页面时,程序将模板以文本方式读入一个String类型变量中,然后依次查找每个数据所对应的tag的位置,用表示数据的字串替换它。在Java中实现字串替换的代码如下:
public void ReplaceStr(String sTag, String sData){
int index;
while((index=sHTML.indexOf(sTag))>=0)
sHTML=sHTML.substring(0,index)+sData+sHTML.substring(index+sTag.length(),sHTML.length());
}
把所有定义的tag替换之后,就创建出一个表示当前操作的结果数据的动态HTML页面。通过程序内置的浏览器在本地打开这个HTML页面,最终实现了将服务结果向用户输出。
7.方法的优缺点讨论
优点:
成功解决了数据共享的问题,因而极大地拓展了浏览器在服务系统开发中的应用领域,从而能够充分利用开发资源,高效的开发出基于网络的数据服务。
以XML作为数据载体,直接以数据的形式返回结果,可读性强,易于调试。
XML的体积较小,可以减轻服务器和网络的负担。
方法不仅限于JAVA程序,在其他开发平台上也可以通过类似的办法实现。
可以通过XSL扩展XML在浏览器上的显示功能,省去创建动态网页的步骤。
缺点:
文本形式的XML存在着不小的安全问题,对一些机密的数据需要加密后传输。
将HTML页面存放在客户端的形式在多台客户机的情况下会对维护和更新页面造成一定的难度,可以考虑在客户端建立一个被动式的远程页面更新服务。
8.结束语
因为篇幅有限,这里只举了一个最简单的例子,但我们仍然能体会到在应用程序的Web服务中使用浏览器所带来的便捷和强大的功能。这种方法突破了数据访问上的束缚,能够最大限度的发挥各自的优势,提高了软件的整体性能,又节约了宝贵的开发时间和精力。
参考文献
1.Mark Birbect 等著,裴剑锋 等译,XML 高级编程(第2版),2002
2.Tom Myers Alexander Nakhimovsky 著,王辉 等译,Java XML编程指南, 2001
3.Bruce Eckel 著,侯捷 译,Java编程思想(第2版),2002
4.Dan Becker, Explore online XML data with Java programming,IBM developerWorks journal.,August 2002