
基于ARM7的MPEG-4视频解码器的优化
2009-06-08
作者:汤霄峰,郑善贤,胡 强
摘 要: 分析了ARM7处理器的结构特点,针对解码器的优化特点和芯片的硬件结构,采用了算法级、语言级、ARM级联合优化的方法,对标准MPEG-4解码过程进行了优化。通过本文所总结的ARM7TDMI上视频解码的优化方法,可以使MPEG4视频解码节约大量的数据处理时间,能较好地满足低分辨率、低帧率场合实时解码的要求。
关键词: ARM7;MPEG-4;视频解码器
目前,手持设备的视频播放非常流行。一直以来,图像压缩大都采用H.263压缩算法,然而,由于MPEG-4标准的成熟,很多视频图像都已经采用MPEG-4算法进行压缩。本文旨在研究基于ARM7微处理器的MPEG-4视频解码器的优化。利用嵌入式系统实现MPEG-4视频解码,处理器的选择是关键。在嵌入式系统中常用的RISC处理器是ARM核,因为它具有体积小、功耗低、成本低、性价比高的特点,这对于移动应用领域非常重要。ARM7系列微处理器为低功耗的32位处理器,最适合于对价位和功耗要求较高的消费类应用[1]。本解码器可以运用于低分辨率和低帧率的应用场合,因此选择在ARM7TDMI核上实现解码功能。要实现更高帧率和分辨率的解码,可将软件直接应用在更高端的处理器上。
1 MPEG-4视频解码算法
MPEG-4标准可以划分为一套子标准,标准的每一部分都有各自最适合的应用场合。MPEG-4 SVP(Simple Visual Profile[2])就是一种特殊的、简单的MPEG-4实现。其专门针对手持式产品中视频传输应用场合制定的。由于本解码器可应用在手持移动设备视频解码的场合,因此选用MPEG-4 SVP作为解码算法。
本文选用ARM7TDMI作为核心处理器进行MPEG-4视频解码器的开发。在实际开发过程中,针对ARM7TDMI的结构和MPEG-4的算法特点,做了大量优化工作,保证了解码精度,大幅度提高了解码速度。严格来说,ARM7处理能力有限,更适合用于控制类型的应用。由于其没有针对视频解码数据处理而进行优化设计,因而不太适合于视频解码等数据处理类应用。但是由于该芯片具有明显的成本优势,所以经过优化,在充分利用其性能的前提下,还是可以作为手机等嵌入式系统的视频解码应用。
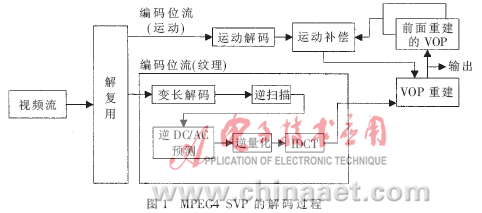
解码过程实际上就是从视频编码码流中恢复出VOP数据的过程。图1描述了一个视频解码过程。解码器主要包含运动解码和纹理解码。I帧中只含有纹理信息,因此只须解码纹理信息即可恢复I帧。而P帧中不仅包含纹理信息,还包含运动信息,所以须解码运动信息,获得运动矢量并进行运动补偿。另外,还须进行纹理解码获得残差值,将这两部分组合起来才能重建P帧[3]。
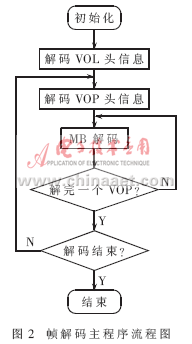 解码器的实现主要是提供一个简单的接口函数,供解码时调用。该接口函数根据解码的不同需要和不同阶段提供了5个入口。5个接口函数中,有 4个供初始化、预处理及后续处理时调用,剩余1个是帧解码的实现函数。图2为帧解码主程序流程图。
解码器的实现主要是提供一个简单的接口函数,供解码时调用。该接口函数根据解码的不同需要和不同阶段提供了5个入口。5个接口函数中,有 4个供初始化、预处理及后续处理时调用,剩余1个是帧解码的实现函数。图2为帧解码主程序流程图。
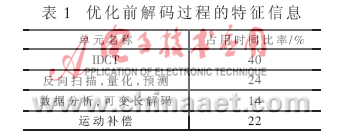
解码过程的计算主要集中在如下几个模块:IDCT、运动补偿MC、逆量化、逆扫描、逆预测以及变长解码VLD。表1给出了优化前解码过程的特征信息。从表1中可以看出,上述运算模块在解码过程中占有很大比例。对以上各模块进行优化的效果将直接反映在解码器的实时效率上。
2 解码器优化
2.1 效率更高的IDCT变换
通常,MPEG-4编码过程中有8×8块在DCT变换后AC系数大都接近于零,经过量化后直接变成了零。同时根据帧间预测的相关性:在运动不是非常剧烈的情况下,量化后大部分DCT相关性是零。表2显示了在快速运动和慢速运动序列下所有全零块的百分比。

对于快速运动序列,大约25%的DCT块是全零;对于慢速运动序列,全零块的百分比大约47%[4]。这样,可以把DCT块分为不同的三类:一类是全零块(DC系数和AC系数都是零),一类是只含有DC系数(AC系数是零),一类是含有DC系数和AC系数,如图3所示(这里用4×4的块举例,D代表DC系数,A表示AC系数)。对于不同的IDCT进行不同的处理:对于第一类情况,全零块,跳过反变换;对于第二类情况,只进行反DC变换,通常除以8,即移3位即可;对于非零AC系数块,按照快速的IDCT处理。这样就可以针对不同的情况采用不同的处理办法,提高了解码效率。

2.2 效率更高的运动补偿
2.2.1 运动补偿的扩边
MPEG-4在进行运动补偿时,使用运动向量在参考图像中寻找预测块。如果运动向量变化比较快,则运动向量很可能指向参考图像以外。MPEG-4标准框架中,采用了很多分支判断语句来处理运动向量指向参考图像以外的情况。一方面IF语句的判断会降低程序的效率,造成解码过程速度的下降;另一方面如果运动向量没有指向参考图像以外,IF判断就显得多余。为了提高解码效率,可以采用参考帧扩边的方式来解决。将参考图像的边界扩大部分全部置零,这样就可以减少很多判断语句,提高解码效率。在实际中,运动向量的有效范围很大,但当运动向量使计算一个预测块所需的像素完全处于参考图像以外时,则不论运动向量的水平分量或者垂直分量延伸多远,所得到的预测块都是相同的。而运动补偿既可以基于块(8×8)的,也可以基于宏块(16×16)的,因此将扩展的字节数取为16就可以了。同时将运动向量的两个分量分别裁剪到不超过参考图像左边和上边的边界8 B以及下边和右边的边界2 B。扩展后的参考图像见图4。

2.2.2 双线性插值的改进
MEPG-4解码算法中,运动补偿是以宏块为单位进行的。最初的做法基于参考图像采用双线性插值,见图5。

对这一做法进行如下改进:对宏块的运动补偿是根据获得运动矢量进行不同的判断,而不是固定采用双线性插值的算法。运动补偿根据从解码数据中获得的水平运动矢量MV_X和垂直运动矢量MV_Y进行,即根据MV_X和MV_Y最低位为0或1的情况分为:只进行直接复制相应数据;只进行垂直方向插值;只进行水平方向插值;进行双线性插值。具体做法如下:
当MV_X和MV_Y的最低位都为零时,运动矢量指向的16×16的块本身与缓冲区中的像素重合,这时不需要进行任何插值处理,直接复制相应数据。当MV_X最低位为零而MV_Y的最低位不为零时,运动矢量指向的8×8的块的点落在某列两相邻像素的中间,这时只需要进行垂直方向的插值。当MV_X最低位不为零而MV_Y的最低位为零时,运动矢量指向的8×8的块的点落在某行两相邻像素的中间,这时只需要进行水平方向的插值。当MV_X与MV_Y的最低位均不为零时,运动矢量指向的8×8的块的点落在相邻四个像素的中心,这时必须同时进行两个方向的插值。由于相邻帧之间具有很大的时间相关性,所以本帧和上一帧大部分数据是相同的。假设上面4种运动补偿情形各占1/4,当进行水平或垂直插值时,运动补偿所占的运算量仅为原来的双线性插值的1/2,比双线性插值约节省一半的计算量,从而大大节省了运动补偿的时间。
2.2.3 像素的并行处理
解码过程中处理的像素是8位,如果运动补偿是在字节或像素的基础上执行,则字节加载和存储将被使用,它是存储器访问中代价最高的操作。因为ARM7是32位微处理器,存储器可以按字读取数据,因此设计出一种有效的运动补偿方法,即在字数据的基础上进行操作。利用这种方法,便可以用一种非常有效的方式同时对四像素进行运动补偿。下面以水平方向的半像素补偿为例,讲述补偿的过程。
首先读入一个字到寄存器中,从低到高的数据依次对应像素0、像素1、像素2和像素3;然后将读码流指针增加1字节,再读取下一个字到另一寄存器中,从低到高的数据依次对应的为像素1、像素2、像素3和像素4。示意图如图6所示。

对于垂直方向和水平垂直方向的半像素补偿,其原理与水平方向相同。在具体函数实现过程中,由解码数据获得当前数据块的运动矢量,根据获得的运动矢量得到当前数据块在参考帧的具体位置,从而得到运动补偿所需要的参考数据块。参考数据拷贝到片内。运动补偿在片内实行,按照字读取数据并根据情况采用不同的半像素插值,提高了程序的执行效率。
2.3 VLD优化
由于MPEG-4变长编码中的码字长度是不定的,而解码器的输入是连续的比特流,码字之间没有间隔符,所以VLC(Variable Length Coding)码表必须判断码字的长度。在通常情况下,VLD(Variable Length Decoding)解码是通过不断搜索和判断得到码字和码长,故解码的时间因码长而异。对于实时处理来说,若该部分计算量过大,将影响整个系统的处理速度。原始查表方法涉及到多次读取和判断,计算量较大[5]。另外,信源符号内容不同,对应码长也不同,造成查表判断耗费的时间差别很大。可以采用基于分组的办法,根据码字编码位的不同划分为多个码表,将码字按照不同的区域进行划分。这样,不断的搜索判断可以简化为三个步骤:(1)读入定长码字;(2)通过对读入数据大小的判断确定读入的符号应属于哪一个查找表;(3)利用得到的码字在查找表中直接获得其对应的信息。因每个分组包含的符号较少,所以可在取出分组信息后,从剩下的信息位中直接得到符号在表中对应的位置。
经分组后,解码过程简化为(按最大码字长度读入数据,以8位数据为例,设分成码长小于3的小码表和码长大于3的大码表):
(1)对读入数据进行大小判断。因分组时考虑到数据大小判断的简便性,可用移位代替。
(2)数据大小的比较。右移5位,判断是否为0。如果为0,则符号落在码长小码表中;否则,符号落在大码表中。
(3)若符号落在小码表中,以右移5位的读入数据作为相对地址,直接在小码表中找到对应非零系数个数和正/负个数及码长。若符号落在大码表中,则直接以读入的数据为相对地址,在大码表中找到相应的信息。
无法预见的反复读取和判断,经过基于分组的解码优化简化成上述三个可预见的步骤,减少了判断次数,加快了处理时间。
3 实验结果与数据分析
通过优化,MPEG-4的解码性能有了较大的提升。在ADS1.2环境下分别对各模块进行C算法优化和ARM代码优化,结果如表3。按调用一次模块函数所需周期数进行统计。

这些模块是解码过程中经常会调用的函数,因此,这些函数的优化将使解码速度有明显提高。
表4比较了不同序列的15帧QCIF格式视频解码优化前后所需的带宽。这些图像具有不同的复杂度,因而结果也不一样。

解码速度基本取决于图像画面的运动情况和颜色是否丰富。从上面的数据可以看出对于不同的序列,其解码速度也不同。news、salesman和miss_am之所以很快,是因为图像背景静止,只有肩部和头部有运动,因而P帧的编码数据量较少,解码速度较高。另外,如果图像很简单(单调),其能量集中到DC系数(直流分量)上,交流系数会出现多个零,因此变长解码速度就会较高,从而节约了解码时间。
通过本文所总结的ARM7TDMI上视频解码的优化方法,可以使MPEG4视频解码节约大量的数据处理时间。由实验结果可见,本视频解码器能较好地满足低分辨率、低帧率场合实时解码的要求。
参考文献
[1] 杜春雷.ARM体系结构与编程[M].北京:清华大学出版社,2003.
[2] ISO/lEI.MPEC-4 video verfication model version 18.0.MPEG N3908,2001.
[3] 钟玉琢,王琪,贺玉文.基于对象的多媒体数据压缩编码国际标准,MPEG-4及其校验模型.北京:科学出版社,2000.
[4] 田纲,胡瑞敏,王中元,等.Trimedia平台MPEG4编码器优化策略.计算机工程与应用,2006(36):78-81.
[5] HE Yu Wen.A platform-based MPEG-4 advanced video coding(AVC)decoder with block level pipelining.PCM2003:15-18,Singapore,2003,12.