
摘 要: 描述了一种基于免疫学理论的入侵检测系统的体系结构,简要说明了系统的特点,介绍了免疫检测器的生成模型和生命周期。
关键词: 免疫学 入侵检测 阴性选择
随着信息技术的发展及网络的普及,网络安全已成为一个不可忽视的重要问题。而传统的IDS只能检测已知攻击,对未知攻击和修改过的已知攻击则显得无能为力。这就迫切需要采用新技术来解决这一问题。1994年,Kephart首次提出了将免疫原理应用到计算机安全系统的思想;1997年,美国新墨西哥大学的Forrest等人提出了构建基于免疫的计算机安全系统的基本原理;1998年,Dasgupta将人工免疫系统(Artificial Immune System, AIS)和多Agent结合起来,并于1999年提出一种多层次框架;2000年,Hofmeyr和Forrest提出一种人工免疫系统模型,并且将它映射到网络入侵检测这个实际的领域。至此,人工免疫系统已经成为网络安全的一个崭新的方向。它通过借鉴生物体的免疫功能,来构建网络系统,从而达到提高网络安全性的目的。
1 免疫系统原理
人的免疫系统能有效区分自我(self)细胞和外来(nonself)病原体,从而保护人体不受大量外来病原体或有机体的感染。其中就是免疫细胞在起作用。免疫细胞可分为B细胞和T细胞。它们表面附着针对某种抗原的抗体,分别在胸腺和骨髓中生成,然后在胸腺中经过一个阴性选择(negative selection)的过程,最终发育成熟。所谓阴性选择,就是将新生而未成熟的免疫细胞与生物体自身细胞进行匹配,如果成功,则将此细胞杀死,只有那些与所有自身细胞都不匹配的细胞,最终才得以脱离胸腺,成为成熟的免疫细胞。之所以要这样,是为了避免发生免疫细胞杀死自身细胞的自免疫反应。匹配过程中所使用的是r-邻近位算法:即如果2个基因链有至少r个邻近位相同,就称它们匹配,其中r是匹配规则的一个参数。为简单起见,用二进制串(0或1)来表示基因链。例如对于r=5,称2个基因链1000111101011010和0101011101101000是匹配的,而1010010001000110和0101001011100010是不匹配的。
免疫细胞生成后,分布到身体各处,密切监视着身体的各个部位,一旦发现异常,就会对病原进行识别并与之结合,从而消灭它。总的来说,人的免疫系统具有分布性、自治性、多样性、特定性和不完全检测性等特点。
大多数计算机安全问题都可看作是区分自我(如合法用户、授权操作等)与非我(如入侵者和计算机病毒等)的过程。所以可以借鉴人的免疫系统的一些特征来构造入侵检测系统:把被监视网络的正常活动作为self集,把非正常活动作为nonself集。
2 基于免疫理论的网络入侵检测系统设计
下面主要考虑以下3个问题:网络数据包特征以及免疫检测器生成过程和整个系统的体系结构。
2.1 网络数据包特征
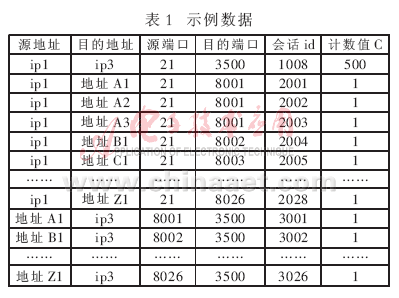
网络IP包由很多域(fields)组成,这些域标明了路由、包的功能以及状态标志等信息。数据包头各域及取值如表1所示,表中分别列出了数据包的IP域、TCP域、UDP域和ICMP域的27种特征以及这些特征的可能取值。其中还有部分域没有列出。需要强调的是,尽管数据包的有效载荷(payload)部分也包含许多对入侵检测有用的信息,但如果把它们考虑在内,将使程序搜索空间骤然增大,进而导致搜索效率急剧下降。因此,这里仅对数据包头进行分析。
从表1可以看出,需要进行匹配的位串长度高达217位,所以很有必要根据随机原则选择部分域进行匹配,以提高匹配速度和系统的处理效率。
2.2 免疫检测器的生成模型及生命周期
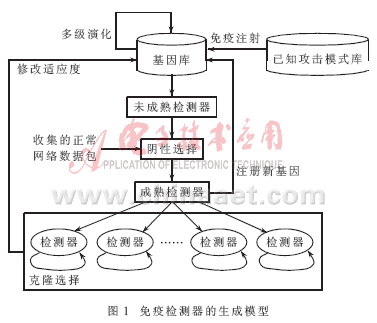
免疫检测器是整个入侵检测系统的核心,其生成模型如图1所示。其中基因库中存放的就是随机生成的针对网络数据包头的免疫检测器。这里所谓的随机,主要包含3个方面的含义:(1)随机选择包头的27个特征的其中一部分。(2)随机选择协议。(3)随机定义各个特征的取值范围。这样就可以显著缩短匹配二进制串的长度。
 (2)分布性:成熟的免疫检测器分布到整个LAN的各个关键主机上,它们分布并行地工作,能够在较小的局部范围内发现并处理入侵。而且整个入侵检测系统具有比较简单的层次结构,能够有效地避免单点故障问题。
(2)分布性:成熟的免疫检测器分布到整个LAN的各个关键主机上,它们分布并行地工作,能够在较小的局部范围内发现并处理入侵。而且整个入侵检测系统具有比较简单的层次结构,能够有效地避免单点故障问题。
(3)自适应性:系统具有较好的自适应能力,能够根据实际情况不断修改检测器的适应度和生命期,使之能更有效地对付入侵。
4 小 结
本文仅提出了一个入侵检测的框架模型,下一步的工作就是在该模型的基础上构筑系统。此外,如何使用尽可能少的免疫检测器来覆盖尽可能大的非我空间等效率优化问题也是将来需要进一步研究的内容。
参考文献
1 Forrest S,Hofmeyr S,Somayaji A.Computer Immunology.Communications of the ACM,1997;40(10)
2 Anchor K P,Zydallis J B,Gunsch G H et al.Extending the Computer Defense Immune System:Network Intrusion Detection with a Multiobjective Evolutionary Programming Approach.In:1st International Conference of Artificial Immune System,Canterbur,UK,2002
3 梁意文,潘海军,康立山.免疫识别器构造的多级演化.小型微型计算机系统,2002;23(4)
从基因库取出部分随机产生的免疫检测器,组成未成熟的检测器集R0,然后使用大量收集来的正常网络数据包作为自我集,利用以上的r-邻近位不完全匹配算法在R0上作阴性选择。通过了阴性选择的检测器则成为成熟的检测器集R。把R注册(复制)到初始基因库中,同时,把它们分布到网络中的重要节点上,就可以进行入侵检测了。
需要注意的是,人体随机生成的免疫细胞有98%被阴性选择所淘汰,仅有2%的免疫细胞能通过阴性选择而存活下来。免疫检测器的生成如同生物体一样,实际是一个时间复杂度非常大的循环往复过程。该过程对于人体这种高度并行的分布式系统来说是可以忍受的,但对于入侵检测系统来说却无法容忍。可以通过对基因库进行多级演化,使其生成合格免疫检测器的几率大大增加,从而使检测器生成过程的时间复杂度降低。
此外,还可使用已知攻击模式库对基因库进行免疫注射。该过程相当于人类打预防针,使之能够识别并抵抗已知攻击。这样做也是为了加快免疫检测器的产生过程并提高产生效率。
不难看出,免疫检测器生成过程的实质就是找出自我空间S,然后用检测器尽可能覆盖非我空间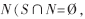
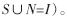 不论已知攻击还是未知的新攻击,也不管攻击过程如何,它们产生的结果都隶属于非我空间。所以,只要免疫检测器能够尽可能地覆盖到非我空间,则它一定可以检测到未知攻击。
不论已知攻击还是未知的新攻击,也不管攻击过程如何,它们产生的结果都隶属于非我空间。所以,只要免疫检测器能够尽可能地覆盖到非我空间,则它一定可以检测到未知攻击。
需要强调的是:成熟的免疫检测器并非永远在系统中存在,而是具有一定的生命周期。这样做有2方面原因:(1)为了保证系统的平衡,使得免疫识别器不会无限制增长。(2)使适应度低的检测器死亡,适应度高的检测器进行克隆选择,从而能够更快地对已知入侵进行响应。每个检测器都具有一定的适应度(设为匹配阈值t的倒数,即1/t)和生命期。如果检测器在规定生命期内匹配不成功或未达到匹配阈值t,则它会自动死亡。此时系统会自动生成一些新的检测器,使系统重新达到平衡;而如果检测器在规定时间内达到匹配阈值t,则它就会被激活,对已有入侵进行反应,并且通过克隆选择过程成为记忆型检测器。系统会延长此类检测器的生命期,并提高它们的适应度,即降低它们的激活阈值t,使得它们更容易存活和被激活,从而使得相似攻击再次到来时,系统能够快速作出反应。
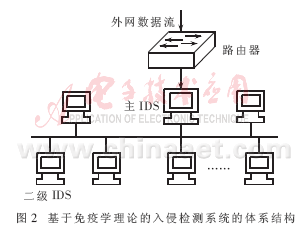
2.3 体系结构
免疫IDS可分为2层:主IDS和二级IDS。这类似于人体免疫系统中的一级淋巴节点和二级淋巴节点。基于免疫学理论的入侵检测系统的体系结构如图2所示。其中主IDS部署在路由器之后,它接收所有来自外网的数据,并根据它们生成免疫检测器,并将成熟的免疫检测器分发到各个主机节点中,使之成为二级IDS。它主要负责检测本机网络中是否有非我数据包存在,并且根据实际情况,进行克隆选择过程。免疫检测器依然是使用r-邻近位匹配规则与数据包进行匹配。
3 系统的特点
由于借鉴了生物免疫系统的一些思想,该入侵检测系统能够有效地检测未知新攻击。此外,它还具有以下特点。
(1)轻量级:由于该系统仅对网络数据包头进行分析,因此处理速度较快,对整个网络速度的影响不是很大。