
文献标识码: A
文章编号: 0258-7998(2013)08-0137-03
在日常生活中,人们一直都在和数据信息打交道。数据信息组织和保存的方式很多,最常用的方式就是把数据信息保存在某种文件中,然后将文件上传到FTP服务器[1]。但是当用户要对文件进行操作时,查找文件会显得比较麻烦。本文提出通过数据库直接记录并管理这些文件中的数据信息[2],通过数据库的SQL语句对相关的记录进行增删查改,操作起来非常便捷,而且在数据库中可以采用集群的技术,为用户提供高可靠性的服务。基于Oracle数据库的上传下载软件实现的主要功能是将一些文件写入到数据库,实现文件的上传;然后再将数据库中的内容读出,实现文件的下载。
本文设计不仅实现了文件的上传和下载,还针对一些较大文件的上传提出了一种分块上传的思想。先指定用户想要的文件块的大小,这个值决定了文件要被分割的块数,较大的文件分割成若干块,每块都以一条记录的形式写到数据库中。当某条记录写数据库失败时,只需将那些写数据库失败的文件块重新上传,不需要将整个文件重新上传。采用这种方式可以提高文件上传的效率,节约重新上传时写数据库的时间。但下载时,如果用户需要完整的原始文件,原来属于同一个文件的分块则需要重新写到一个文件中。本文使用边下载、边合并的方法,实现了分块文件的合并下载。用户可以根据自己的需要,针对性地下载其中的部分文件块。读取一个文件分块相比读一个完整的大文件要快很多,文件的分块与合并提高了文件的上传下载效率。值得注意的是,在设置文件分块时,分块的大小要适度,否则会影响软件的运行效率[3],用户可以根据实际要求设置文件分块的大小。
1 大文件分块上传和下载软件的实现
1.1 文件的分块
将一个较大的文件上传到数据库时,上传速度往往会受到网络宽带的影响。针对较大文件的保存与管理,需对其进行分块,可以根据网络的带宽设置文件块的大小,假设每个文件上传的时间不超过5 s,设带宽为k Mb/s,文件块的大小BlockSize可以设置的范围最好能够满足式(1):
(5×k/8)MB<BlockSize<(5×10×k/8)MB (1)
若文件块的大小用BlockSize表示,则文件分成的块数nCount与文件的大小之间的关系为:
nCount=Flength/BlockSize+1 (2)
K=Flength%BlockSize (3)
其中Flength代表原始文件的大小,K代表最后一个文件分块的大小。因为文件的大小与文件块的大小不一定刚好是整除的关系。最特殊的情况就是某文件的大小刚好小于文件块的大小,此时的文件就只有一块,即该文件本身。
1.2 分块文件的上传
将分块文件上传到数据库之前,首先要在数据库中创建一个存储文件信息表,并定义相关的字段,方便用户查询和管理[4]。数据库表中主要的相关字段包括:文件编号、文件名、文件大小、基本路径、相对路径、文件块大小、文件块编号、文件类型、文件内容等。
文件上传到数据库主要步骤为:(1)将文件的名称、路径、大小、类型等基本信息写入数据库;(2)根据这些基本信息查找对应的记录,并将文件的内容写到blob字段中,文件内容以二进制的形式存贮在数据库中[5-6]。
文件分块上传时,首先连接服务器端的数据库,在数据库连接成功的条件下,遍历要上传的文件所在的路径。当查找到要上传的文件时,根据文件分块的大小,计算文件分割的块数和最后一个文件块的大小,从第一个文件块开始,计算过程如下:
(1) 判断是否成功连接到数据库。
(2) 判断这是否为最后一个文件块,如果是,则从文件中读取最后一个文件块,写入数据库后结束;否则从文件中读取BlockSize个字节。
(3) 用Insert命令在对应的表中写入文件的编号、文件名称、文件大小、文件的基本路径及相对路径、文件类型、文件块的大小和编号。
(4) 通过文件编号、文件路径,文件名称和文件块编号查找相应的记录。
(5) 将要写入数据库的文件内容保存在一个安全数组中,并调用AppendChunk()函数将该块文件内容填到对应的blob字段当中,并更新记录。
(6)为写入记录中的文件的路径、文件名以及文件块编号设置标记,方便重新上传时定位断点的位置,跳转到步骤(1)。
文件分块上传的流程图如图1所示。
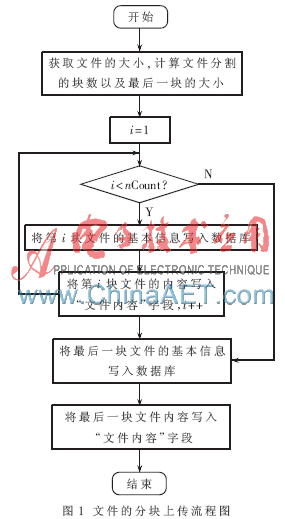
如果服务器数据库与客户端的连接断开,将导致文件上传失败。在客户端与服务器端数据库重新建立连接后,需要续传文件,同时要通过断开数据库时的标记,找到上次上传文件的断点。
续传文件时,为了找到文件续传的起始位置,依然要遍历文件所在的路径,通过文件路径和名称找到对应的文件,再使用文件块的编号和文件块的大小获取下一次文件要上传的位置。设offset为文件指针的偏移值,BlockNo为文件块的编号,BlockSize为文件块的大小,三者之间的关系如下:
offset=BlockNo×BlockSize (4)
式中,被标记文件块的编号BlockNo乘以文件块的大小BlockSize,就是续传时读取文件的偏移值。通过这个方法,就可以找到断点所在的文件块位置,实现文件的续传, 从而避免重新上传之前已经写入数据库的文件块。
1.3 分块文件的下载
因为文件是保存在数据库中的,用户可用通过SQL命令对数据库中的记录进行增删查改等操作,这比存储在FTP服务器中的文件处理要方便很多。下载的过程其实就是上传的逆过程,思想相似。
下载时根据相关的查询条件,如果存在符合条件的记录,即可对这些记录保存的文件进行下载,在成功连接到数据库的条件下,从第一条记录开始执行以下过程:
(1)判断是否成功连接到数据库。
(2)判断该记录是否超过最后一条记录编号,如果是,下载结束;否则跳转到步骤(3)。
(3)从记录中获取文件的类型、文件名以及相对路径,判断该文件是否已经存在,如果不存在,则根据文件的类型创建一个文件,以可追加的形式打开文件。
(4)调用GetChunk()函数获取blob字段中的内容,并保存在一个安全数组中,最后将安全数组中的数据写入文件。
(5)关闭文件,并标记该记录中的文件路径、文件名以及文件块编号,并跳转到步骤(1)。
1.4 分块文件的合并
本文虽然实现了文件的分块下载,但是在实际情况中,人们通常希望使用完整的文件,而不是一个文件块,所以在下载的过程中需要将各个文件的分块重新合并成一个文件。本文采用的方法是在下载的过程中即可进行合并操作,文件合并下载的流程图如图2所示。
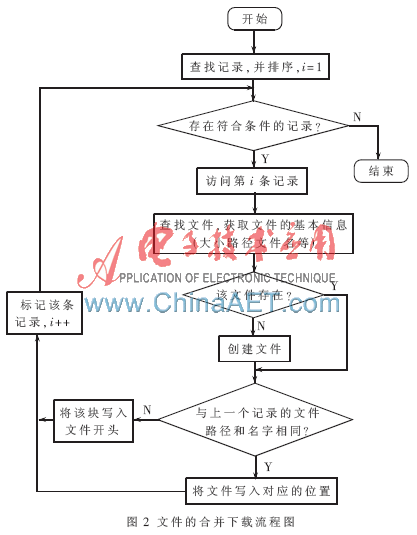
文件的合并是文件合并下载过程中的一部分,即每次下载某条记录中的文件内容时,先判断该文件块将写入的文件。
用户根据文件名称,文件路径等信息查找所需要的文件,如果存在符合条件的记录,就依次访问这些记录,并将每条记录中的文件内容读取出来,写入相应的文件中。从查询到的第一条记录开始:
(1)判断是否已经访问了最后一条符合条件的记录,如果是,则结束,否则转到步骤(2)。
(2)获取文件的路径、文件名称、文件类型等基本信息, 判断当前路径下是否已经存在这样的文件,如果不存在,将创建一个对应的文件;否则跳转到步骤(3)。
(3)将记录中的文件相对路径、文件名两个字段的内容与上一条记录中的相对路径和文件名匹配,如果相同,则将文件内容追加到该文件;否则根据该文件块的基本信息重新创建一个文件。
(4)标记该条记录并移到下一条记录,并跳转到步骤(1)。
所有记录被访问完的同时,所有的文件分块都被写入了相应文件中,既不会出现文件内容的覆盖问题,也不会额外地占用存储空间。
2 实验分析
通过测试发现,文件的完整上传所消耗的时间最短,但是上传失败后要重新上传整个文件。如果使用文件的分块上传,文件分块的大小要适当,分块越多,上传的速度就越慢。因为记录每个分块文件的基本信息也要消耗一定的时间,在上传失败需要重新上传的情况下,只需上传剩下的没有上传成功的文件,效率有所提高。在下载的过程中,单块文件明显比整个文件的下载要快,因为单块文件下载只需要读取块数据。而文件的合并下载时间比整块文件下载时间要长,因为在合并的过程中要判断各个文件块是否来源于同一个原始文件,会消耗一定的时间。
相对于普通的将文件上传到FTP服务器,本文实现了基于Oracle数据库的大文件分块上传下载应用软件,将文件的内容以二进制的形式分散保存在Oracle数据库中,这不仅可以对大量数据信息进行管理,还可以使得不同的用户共享很多数据信息。文件的分块上传采用文件分割技术,将文件分块保存在数据库中。通过文件的续传,避免了由于各种网络原因导致的写数据库操作失败,需要将整个文件重新上传的问题。文件的合并下载解决了同一个文件中不同分块的合并问题,避免了先下载文件再进行合并的做法,提高了软件的运行效率。
参考文献
[1] 冯素梅.基于FTP的文件上传与下载研究[J].北京电力高等专科学校学报(自然科学版),2010,27(5):197-199.
[2] 陶宏才.数据库原理及设计[M]. 北京:清华大学出版社,2007.
[3] 张翼.BLOB数据优化算法及其应用[J].计算机测量与控制,2011(6):1478-1480.
[4] 徐孝凯,贺桂英.数据库基础与SQL Server应用开发[M].北京:清华大学出版社,2008.
[5] 谢华成,张昆朋,范黎林,等.基于文件分割的二进制大对象存取算法[J].计算机应用,2011,31(10):2612-2616.
[6] 赵宇峰,张烨.VC存取数据库的BLOB类型的方法[J].微型电脑应用,2007,23(3):59-60.