
文献标识码:A
文章编号: 0258-7998(2014)07-0116-03
对业务系统连续性要求较高的企业或机构,其数据安全极为重要[1]。传统的RAID、远程镜像、周期性备份和快照等技术都会引起数据丢失的问题[2-4]。因此对数据可靠性和安全级别要求较高的业务部门急需存储系统能提供连续数据保护(CDP)功能[5]。
国内外在CDP系统研究方面已经开展了大量研究[6]。但这些工作主要集中在存储架构设计、存储空间优化和一致点恢复等方面,对快速恢复研究不多。针对海量的块级变化数据,设计高效快速的索引方法是个研究难点。本文主要针对卷级系统历史数据索引和查询的优化,提出一种面向连续数据的分时分段的层次式快速索引方法HSTIM(Hierarchical Spatial-Temporal Indexing Method)。
1 HSTIM设计
在磁盘逻辑卷层次,数据由连续的数据块组成。每个数据块有固定的大小,并通过逻辑块地址LBA来标识。连续数据保护实现的关键技术是对数据变化的记录和保存,以便实现任意时间点的快速恢复。CDP一般有3种实现方式:基准参考数据模式、复制参考数据模式和合成参考数据模式[7-8]。其中,合成参考数据模式是前两种模式性能的折衷,较好地实现了前两种模式的妥协,因此可以得到较好的资源占用和恢复时间效果,但需要复杂的软件管理和数据处理功能,实现比较复杂。
1.1 分时分段索引数据组织
HSTIM中索引数据按分时和分段策略组织,数据组织如图1所示。图1例中在t3~t4时间段内共产生N+1个索引文件(元数据单独索引)。段区间的长度采用不等成划分方法,长度按磁盘写IO密度来确定。索引文件记录了Rt(a) ,即t时刻逻辑地址为a的增量数据在增量存储空间的位置。为加速索引的读取速度,可采用多个物理硬盘存放索引文件。

1.2 索引快照
索引快照提取了一个时间段的索引阶段结果。在图2的例子中,t1和t2两个时刻插入了索引快照。所有索引快照结果存放至一个独立的索引文件,如图2的右侧的索引快照独立索引文件。快照独立索引文件采用OVBT索引方式。如果用户需要查询图1中t时刻的索引结果,则可通过先查询索引快照获得t1和t2时刻的索引,然后查询t2~t时刻的索引,最后将索引结果进行合并即可。HSTIM通过索引快照避免了索引数据的全查询,加快了特定时刻索引的快速查询,尤其适用于历史数据保护时间窗口较长的应用场景。由于索引快照文件较小,在实现上没有采用分段策略,即将LBA地址从0~MAX索引快照存放至一个索引文件中。

1.3 增量式快速查找
HSTIM通过改进OVBT索引节点结构实现了增量查找支持。原先的OVBT内部节点包括了引用数目和分裂值列表。HSTIM中的内部节点通过新增时间戳列表实现了增量查找。HSTIM和OVBT的内部结构比较如图3所示。

卷级CDP一次IO更新产生一条索引记录项,索引记录项可用{LBA,timestamp,R}表示,其中LBA表示IO的LBA地址,timestamp表示时间戳,R代表数据在存储池中的位置。OVBT索引需要对每一个索引项进行记录,针对每一个IO的时间戳生成一个独立的B+树索引。OVBT有两种类型的节点:叶子节点和非叶子节点。两种节点由通用的索引项{ref, entries}组成,其中ref表示节点被引用的次数,entries 由{entry, entry,…, entry}列表组成。每个entry由{key, timestamp, info}3个元素构成。对叶子节点,key表示IO的LBA地址,timestamp表示时间戳,info表示数据在存储池中的位置,即索引记录项中的R。对非叶子节点,key代表B+的分裂键值,timestamp代表所指向下一层节点的插入时间,info是指向下一层节点的指针。
为记录每一更新IO产生的B+树的根节点,OVBT维护一张根节点记录表(root table)。根节点记录表由{root, root,…, root}列表组成,每个root项由{timestamp, ptr}组成,其中timestamp代表独立B+树的产生时间,ptr指向B+树的根节点。
2 性能评测
2.1 测试方法和实验平台
通过对实际应用中的IO trace文件进行回放的方式对HSTIM性能进行了评测。测试选择的IO trace是Msr-cambridge Trace。该Trace文件采集了企业数据中心13台服务器上共36个磁盘卷连续14天的块级数据。实验选取文件集合中数据量最大的文件CAMRESISAA02_ lvm1.csv(以下简称AA02_Trace)作为样本。所有的IO请求块都按最小磁盘扇区大小(512 B)进行了等长切割和对齐存储。实验平台主要硬件包括Pentium(R) Dual-core E5200 2.50 GHz处理器、4 GB DDR2内存和500 GB Seagate ST3500620A硬盘, 操作系统是Windows 7。
2.2 HSTIM与B+-tree和OVBT性能综合比较
实验对AA02_Trace文件进行了24 h的数据回放,经统计在24 h内,系统共产生8 660 679个IOR (写IO请求)。如果对每个IOR按512 B等长切割,则共产生224 356 508个对齐的块级IO(Aligned Block IO,以下简称ABI),表1给出了AA02_Trace文件24 h内的写IO统计结果。为描述方便,本实验中对HSTIM采用了等长分时,时长分别为0.5 h和2 h,分别称HSTIM-0.5和HSTIM-2。实验从索引文件大小、插入性能和查询性能三方面对HSTIM、B+-tree和OVBT进行了综合比较,给出了周期为2 h的性能统计结果。
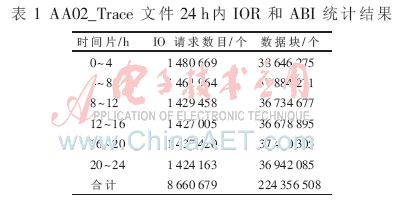
(1)查询性能比较
表2给出了OVBT与B+-tree的查询性能比较。实验表明,B+-tree的查询速度在RPO小于5 h可以接受,基本在1 min内得出查询结果。但在RPO大于5 h的情况下,查询性能急剧下降,在RPO=6 h查询时间为838 s,RPO=12 h查询时间长达2.27 h。对OVBT而言,由于每一个时间点索引数据由一颗独立B+树组成,查询时间相对稳定。RPO小于12 h内任意点查询时间小于44 s。本实验同时说明,传统的分别对LBA和Timestamp建立B+-tree的索引方式不适合大数量的任意点恢复索引的需要。
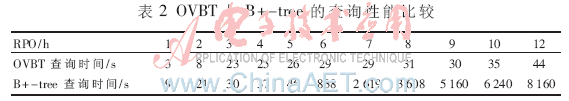
HSTIM由于采用分时策略并将分时索引快照独立组织,因此查询时间包括索引快照查询时间和时间段内索引查询时间。图4给出了HSTIM-2、HSTIM-0.5和OVBT的查询性能比较。实验结果表明,HSTIM在查询性能上较OVBT有较大提高。在RPO=24 h,HSTIM-0.5的查询时间仅为OVBT的11.6%。HSTIM-0.5与HSTIM-2相比,由于分时频率高,因此查询索引快照时间略长于HSTIM-2,但时段内的索引查询速度明显少于HSTIM-2。但从整体上看,HSTIM-0.5和HSTIM-2的查询速度并无大的差别。
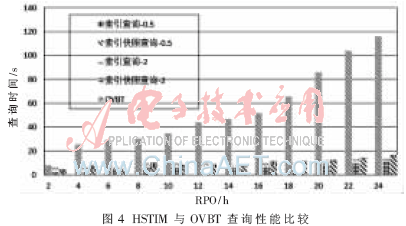
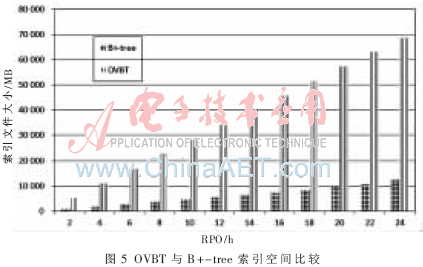
(2)索引空间消耗比较
图5给出了OVBT与B+-tree索引空间比较结果。测试表明,OVBT索引存储空间平均是B+-tree的5.2~5.5倍。由于OVBT内部有大量重复数据,采用压缩工具对索引文件进行压缩,压缩后的OVBT索引文件大小平均仅为原索引文件的3%。但压缩带来的问题是,恢复时需要引入额外的解压缩时间开销。为减少存储空间,在实际应用中可以将离当前时间点较远的索引文件压缩存储。
本文针对卷级CDP任意点恢复提供了一种快速的索引方法-HSTIM,并对该方法的性能进行了评估。实验结果表明,在一定的备份窗口内,HSTIM能为卷级CDP任意点的恢复提供快速索引支持。高效的索引可快速定位到变化数据在增量空间中的存放位置,解决恢复中数据“在哪里”的问题。
参考文献
[1] 梁知音,段镭,韦韬,等. 云存储安全技术综述[J].电子技术应用, 2013,39(4):130-132.
[2] SMITH D M. The cost of lost data[J]. Journal of Contemporary Business Practice, 2003,6(3):113-119.
[3] PATTERSON D, BROWN A, BROADWELL P, et al. Recovery oriented computing(ROC): motivation, definition, techniques, and case studies[R]. Computer Science Technical Report UCB/CSD-0201175, San Francisco: U.C. Berkeley, 2002:997-1013.
[4] SANKARAN A, GUINN K, NGUYEN D. Volume shadow copy service[J]. Power, 2004,14(2):2272-2284.
[5] SNIA. Continuous data protection-solving the problem of Recovery[EB/OL].(2008-08-08)[2014-02-22].http://www.snia.org/forums/dmf/knowledge/white_papers_and_reports/CDP_Solving_recovery_20080808.pdf.
[6] SNIA.DMF-Getting_started_with_ILM-20050415[EB/OL].(2005-04-15)[2014-02-22].http://www.snia.org/forums/dmf/programs/ilmi/DMF-Getting_started_with_ILM-20050415.pdf.
[7] PIERNAS J, CORTES T,CARC′IA J, DualFS: a new journaling file system without meta-data duplication[C]. In Proceedings of the 16th International Conference on Supercomputing. New York: ACM press, 2002:146-159.
[8] KAVALANEKAR S, WORTHINGTON B, ZHANG Q, et al.Characterization of storage workload traces from production Windows servers[C]. In IEEE International Symposium on Workload Characterization, IEEE press, 2008:671-686.