
基于神经网络的声测法车辆类型辨识的应用研究
2009-05-07
作者:乔维德
摘 要: 介绍了基于多层前馈神经网络的学习训练方法、运用噪声测量原理和方法判别汽车类型的识别系统,为汽车交通管理和监测统计提供了有力的依据和手段。
关键词: 汽车 神经网络 噪声 识别
 随着我国高速公路和汽车技术的迅猛发展,汽车行驶速度越来越高,极需一种更有效的交通管理系统。这种系统应能自动识别汽车,并能准确判断出汽车类型。20世纪50年代以来,点测式设备如环形线圈检测器,主要用于十字路口的交通控制和交通数据收集。这种探测系统通常利用埋置于路面下的电感线圈,通过电磁感应识别汽车,但这种系统存在着铺设费用昂贵、维护困难、不能将汽车分类等缺陷。利用声测法,并将此经过神经网络的训练,能够有效地识别路面上通过的汽车的类型。
随着我国高速公路和汽车技术的迅猛发展,汽车行驶速度越来越高,极需一种更有效的交通管理系统。这种系统应能自动识别汽车,并能准确判断出汽车类型。20世纪50年代以来,点测式设备如环形线圈检测器,主要用于十字路口的交通控制和交通数据收集。这种探测系统通常利用埋置于路面下的电感线圈,通过电磁感应识别汽车,但这种系统存在着铺设费用昂贵、维护困难、不能将汽车分类等缺陷。利用声测法,并将此经过神经网络的训练,能够有效地识别路面上通过的汽车的类型。
1 声测法汽车类型识别系统
声测法汽车类型识别系统工作原理框图如图1所示。
声测法汽车类型识别系统的工作原理是:当汽车通过时,麦克风将其产生的声波的声压信号通过连接器传到分类系统,通过A/D转换器将声压信号转化为一系列离散的数字信号,并在频谱分析仪中进行频谱转换(FFT转换)。
神经网络为衰减器接受到的每个矢量提供一个分类指示器。每个矢量显示一个预定的间歇时间,即允许产生声音的物体有一个短暂的时间间隔(如0.1秒)。这样,神经网络每隔0.1秒为每种声音产生一个分类指示器,独立地为每个矢量分类。时间积算器是经神经网络分析后的一种分类指示器流量的处理器,即时间积算器经多次与运算结果结合,产生整个系统输出的最后分类结果。
基于神经网络的声测法汽车类型识别系统采用低廉的传感器材,对汽车的类型识别有很好的效果,而且应用的覆盖范围更广,不受天气和光线的影响。
2 神经网络学习训练算法
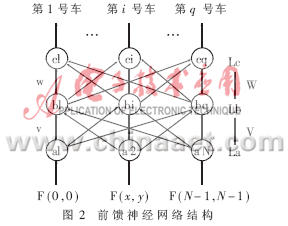
对原始噪声进行预处理之后,余下的识别工作就由神经网络来实现。本文所设计的网络是三层前馈网络,其结构为:输入层有n个节点,n=Np×N;隐含层有P个节点,输出层有q个节点。q个输出节点分别对应q种车型,输入层采用的输入值为傅立叶变换后的值,隐含层和输出层的活化函数为Sigmoid函数。训练完毕后,当输出层的第i个节点输出值大于0.99而其它节点的输出值小于0.11时,就认为本次识别的车型为第i号车。网络结构如图2所示。
采用的训练算法是BP算法,该算法中的误差函数是:
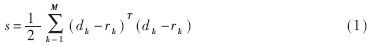
其中,dk和rk分别是网络的希望输出矢量和实际输出矢量,M为训练样本对。
BP算法的一个突出缺点是学习速度慢,原因是多方面的,如与网络的结构有关,与学习算法本身存在的缺点有关。当利用上述误差函数来调整权重时,从推导知道权重调整量总包含下面的因子:

从上式可以看出,当输出层单元i的实际输出ri接近于0或1时,误差信号中的因子式ri(1-ri)使得误差信号变得很小,这时如果输出层单元i的实际输出ri与期望输出值di相差很大时,没有产生强的误差来修正权重,从而延长了学习过程。另外由于激励函数f(x)=(1+e-x)-1是一个饱和函数,当它趋于饱和状态时,导数就接近于零,从而造成收敛速度减慢。由此可以考虑将因子ri(1-ri)从误差函数对权重偏微分的结果中去除,于是可把BP算法的误差函数改进为:
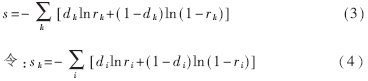
因为0
利用链式微分规则得:

右端第一项表示输出矢量中第i个分量对偏差的影响,第二项则表示权系数对输出分量的影响。根据式(4)计算第一项的偏微分:

其中,bj>0为上隐含层的输出;式(9)就是在ωij空间中sk响应曲面上的负梯度方向。
这样,对权矩阵[W]中的任一元素ωij有:

这可以看出对权值的修正和梯度下降方法之间的关系,由此说明这种误差修正方法对权值的调整是收敛的。利用误差函数为(3)式的改进,BP算法确实把ri(1-ri)因子从误差函数对权重偏微分的结果中消除了。从实际的训练来看,利用本算法对权值修正时,能很快地收敛。
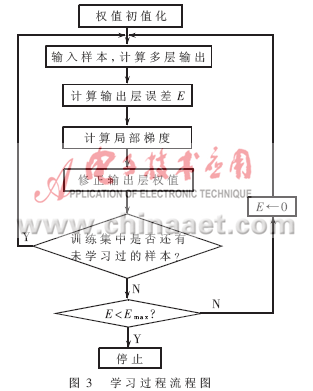
把论文中的BP算法和改进BP算法分别进行了网络训练(选取了4种车型,即q=4),并用到实际交通线路上进行检验。每种车型的样本为实际应用中不同情况下的4套样本(小型车、中型车、重型车、超重型车),这样用16套噪声作为训练样本,并且设定隐含层的节点为p=16。网络学习过程流程图如图3所示。
在网络结构完全一样的情况下,采用(1)式的误差函数进行训练,需要交叉训练2万次后,才可以在实际中运用,可使输出精度达到0.99;而采用改进后的误差函数(3)式进行训练,只需200次,就可以达到同样的精度,并能投入到交通线上在线识别汽车类型。试验结果如表1所示。

从试验结果来看,利用改进BP算法可以使网络的学习速度加快,能很方便地运用于实际生产线。即使有新的车型出现在交通线上,也可以很快完成网络的训练。试验结果测得识别错误率小于1%,并且对汽车的识别效果比统计的方法好。利用改进BP算法后,提高了学习速度,为神经网络识别投入实际应用特别是运用到车流量很大的交通线上,提供了一种有效的方法。从实际应用来看,用神经网络识别比用特征统计识别的容错性要高一些,也优于特征统计方法。在实际中如果有新的车型要增加,只要把网络的结构稍作改进就可以了。
参考文献
1 P.G.J.Lisboa.现代神经网络应用.北京:电子工业出版社,1996
2 崔胜民.神经网络在汽车中的应用.世界汽车,1995(2)