
一种基于ADBMS6830的液冷电池管理系统设计[嵌入式技术][汽车电子]
发表于:2026/3/18 下午4:25:35

面向无人机的高速数据采集及回放系统设计[嵌入式技术][航空航天]
发表于:2026/3/18 下午4:16:42
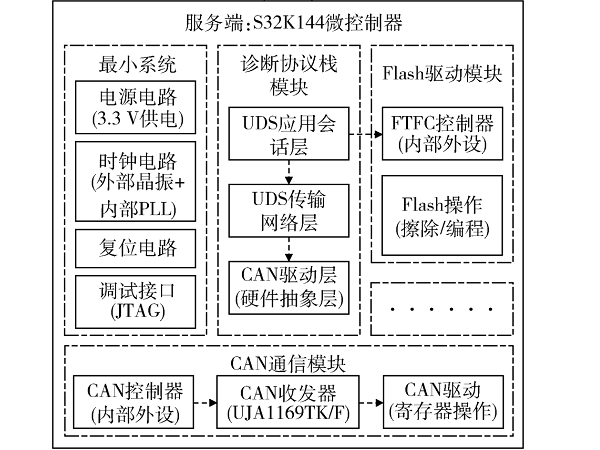
基于UDSonCAN协议的车载ECU Bootloader开发[嵌入式技术][汽车电子]
发表于:2026/3/18 下午4:09:42
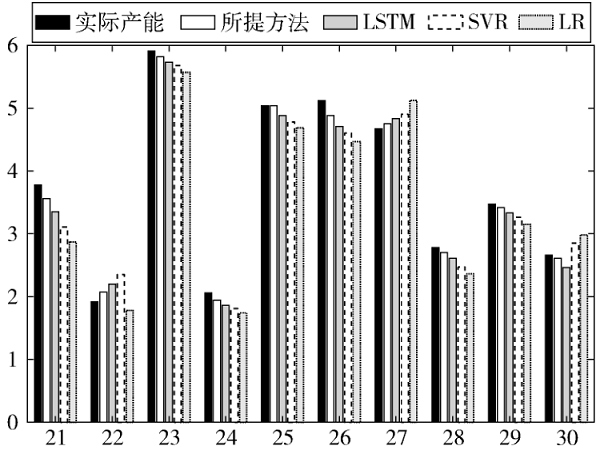
基于SAE特征优选和Bagging集成学习的油藏初期产能预测[人工智能][其他]
发表于:2026/3/18 下午4:02:16

基于图像金字塔与双线性插值的点云融合研究[模拟设计][智能电网]
发表于:2026/3/18 下午3:55:06

基于图像拼接的输电线路覆冰重量估计研究[模拟设计][智能电网]
发表于:2026/3/18 下午3:47:15

混合双通道主动降噪算法的抗干扰优化研究[微波|射频][消费电子]
发表于:2026/3/18 下午3:39:29
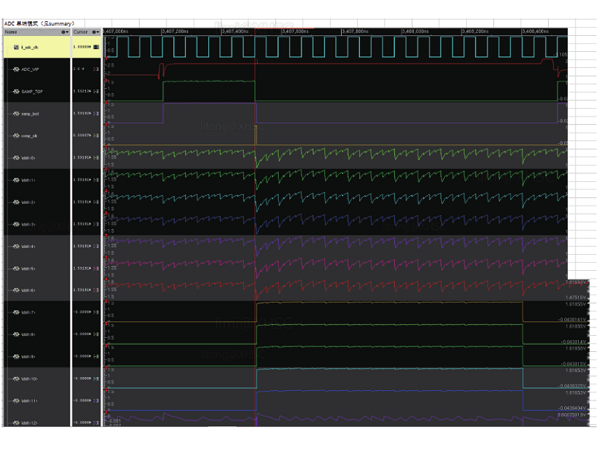
基于SoC的数模混合验证的平台实现方法[模拟设计][通信网络]
发表于:2026/3/18 下午3:31:31

大数据综合信息处理SiP电路设计[EDA与制造][工业自动化]
发表于:2026/3/17 下午5:05:15
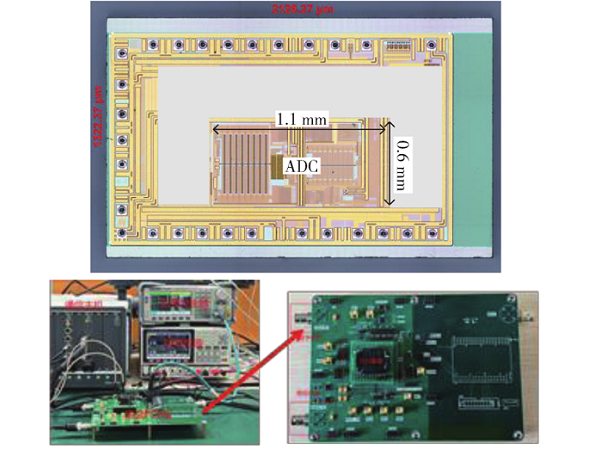
一种16位指令驱动型逐次逼近型模数转换器[模拟设计][物联网]
发表于:2026/3/17 下午4:59:21