
基于DSP的图像旋转算法数据调度策略
2008-07-23
作者:李筱琳1,冯 燕1,何亦征2
摘 要: 为了在DSP平台上实现实时大图像旋转" title="图像旋转">图像旋转,结合TMS320DM642的性能结构特点,针对旋转算法中严重影响DSP CPU效率发挥的大量非连续图像像素地址访问的问题,提出了基于视口图像块覆盖的DSP图像旋转算法数据调度策略" title="调度策略">调度策略,对算法的结构流程进行了优化调整。
关键词: 大图像旋转;数据调度;DM642;DSP;实时;优化
图像旋转是一种应用广泛的数字图像处理技术,随着应用水平的不断提高,对在嵌入式系统中实现高分辨率大图像旋转的需求也越来越高。如在航空领域的高分辨率数字地图图像的显示处理过程中,由于现有的显示芯片均不能支持图像旋转功能,就需要在资源有限的嵌入式平台上实现大幅面地图图像的实时旋转。采用DSP平台是一种实现方式,具体实现时需仔细考虑两个方面的问题,一是选用计算量小的旋转算法,二是充分发挥DSP平台强大的并行计算能力。
目前,已经有很多有效降低计算量的图像旋转算法,基于图像线性存储结构" title="存储结构">存储结构的旋转方法[1]就是其中之一。然而,在DSP平台上,有限的高速存储资源限制了这些算法效率的直接发挥,需要针对算法及DSP平台的性能结构特点进行高效的数据调度。对于图像旋转问题而言,数据调度还需要克服由于存在大量非连续图像像素地址访问而严重影响DSP数据存取及CPU效率发挥的问题。这是图像旋转本身的特殊性,在其他图像处理技术中是不存在的。本文主要讨论如何利用TI公司TMS320DM642芯片的资源特点,进行高效图像旋转的大规模数据调度,从而实现适用于大图像的DSP实时图像旋转。
1 基于图像线性存储结构的旋转方法介绍
目前,图像旋转大多采用基于视口映射的处理。视口是指屏幕上的显示区域范围,方法是先计算出旋转后视口图像像素在源图像中的坐标地址值,再依据该地址在源图像中对应读取像素值,最后利用读取的像素值进行插值,得到最终旋转后视口图像。实际上,由于存在对称性,一幅图像任意角度的旋转可分解为一次90°或180°或270°的旋转,再加上一次±45°以内的旋转。
传统的图像旋转一般通过矩阵乘法实现:
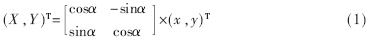
其中,α为旋转角度。
本文选用的张克黛[1]等人提出的基于图像线性存储结构的旋转方法是一种理论上运算效率较高的方法。下面具体介绍。
由于图像是线性存储的,各个像素点之间的相对位置关系确定。如图1(a)所示,图像旋转前,任意像素点P(x,y)和P1(x1,y1)、P2(x2,y2)及A(xA,yA)在几何上是矩形的四顶点关系。由于旋转变换是线性变换,如图1(b)所示,图像旋转后,各个像素点之间的相对位置关系不发生变化,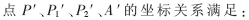

所以,对图像作旋转变换,只需对第一行和第一列的像素用式(1)作矩阵乘法运算,对除第一行和第一列以外的像素,用式(2)进行简单的加减运算即可。这样避免了对整幅图像的每个像素作矩阵乘法运算,可节省5~6倍的CPU周期。
另外,对于旋转计算后非整数像素地址的插值,本文采用双线性插值法,基本能够满足对图像质量的要求。
2 图像旋转的DSP结构优化
2.1 TMS320DM642结构特点
该芯片的结构如图2所示,它基于C64x内核,采用TI的第二代高级超长指令字结构,可在600MHz时钟频率下工作,每个指令周期可并行8条32位指令,可达到4 800MIPS的峰值计算速度。DM642具有64个增强DMA(EDMA)通道,可进行高效的一维及二维数据传输,二维数据传输可用于一个矩形图像数据块的高速搬移。
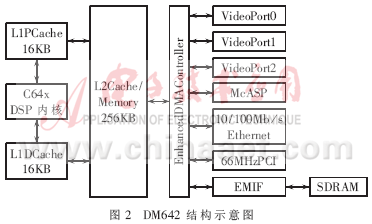
DM642的存储空间由片内和片外两级存储体系构成,其中片内存储器" title="内存储器">内存储器又分为L1和L2两层。第一层L1为CPU Cache,其访问速度与CPU的速度相匹配,包括相互独立的L1P(16KB)和L1D(16KB);第二层L2(256KB)具有灵活的RAM/Cache分配。片外存储器具备32位的访问地址,通过EDMA控制器和EMIF外部存储器接口进行数据访问。其中,片内存储器和片外存储器在访问速度方面存在很大差异。
此外,作为多媒体处理专用芯片,DM642具有用于视频数据I/O的专用接口,易于实现视频信号的显示输出。
2.2 旋转算法的结构优化
针对DM642性能结构特点的算法结构优化,其目的是使上述大图像旋转快速算法的效率能够在DSP平台上得到充分发挥,其核心思想是合理优化存储空间分配和数据传输流,使CPU能连续不断地处理图像数据,消除处理过程中的等待延迟。
由DSP的结构特点可知,只有在数据和程序均位于片内存储器当中的条件下,DSP的效率才能得到最大化的发挥。在大图像旋转算法中,由于涉及的图像数据量远大于DSP的片内存储器容量,源图像和最终视口图像等数据必须被存放在片外存储器中。在这种情况下,为了保证DSP CPU高速处理能力的发挥,必须优化数据流,将源图像分块,依次搬移至片内处理,并设法保证CPU当前要处理的图像数据块已经事先在片内存储器中准备好了。因此在算法整体优化结构上采用Ping-Pong双缓冲" title="双缓冲">双缓冲技术,利用EDMA与CPU并行工作来隐藏图像数据块在片内和片外之间的传输时间,使CPU能连续不断地处理数据,中间不会出现空闲等待。
Ping-Pong双缓冲是一种同时利用两个数据缓冲区的数据传输技术,它将SRAM分成两大块,一块用于存储源图像块,另一块用于存储旋转后的图像块;每一个存储块又分为两个区(Ping区和Pong区),轮流用于图像块传输和处理。其具体并行工作流程如图3所示。
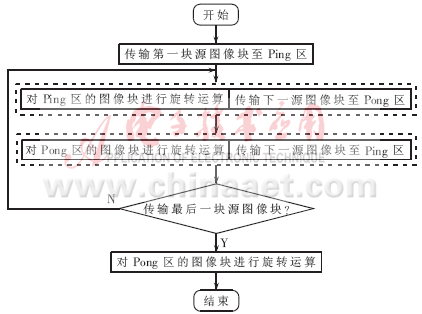
图3 Ping-Pong双缓冲处理技术
至于如何在Ping-Pong双缓冲数据传输机制中设计和安排传输的图像数据块,则必须考虑针对图像旋转本身的特点,设计出具体的适用于旋转算法的DSP数据调度策略。
3 旋转算法的DSP数据调度策略
旋转算法的数据调度目的是使算法能够按照一定的规则,将源图像数据有规律地分块,并按次序分别传输到DSP片内存储器中,完成计算后,形成视口图像块,再将视口图像块按同样的顺序进行排列,形成旋转后的视口图像。整个过程要求调入和调出的图像数据均是规则分块的,并且调入的源图像块中应该包含计算视口图像块的过程中所需要的全部像素数据,尤其需要解决其中的大量非连续图像像素地址访问问题,这样才能正确地发挥DSP EDMA和Ping-Pong双缓冲技术的性能。
3.1 非连续像素地址访问
Ping-Pong双缓冲数据传输机制中图像数据块在片内、片外存储空间的传输,主要依靠EDMA设置,在后台进行二维数据传输。Ping-Pong双缓冲数据传输机制下的EDMA的数据传输要求待传输的图像块具有统一的规律,即每次旋转的图像数据的传输过程不应该因旋转角度的变化而改变。
但是,旋转后的视口图像像素的地址排列与其在源图像中的不同,不再具有连续的地址变化特征,并且视口图像的像素地址在源图像中的排列关系随旋转角度的变化而变化,没有固定的规律,给Ping-Pong双缓冲数据传输机制下的EDMA的数据传输操作带来很大困难,从而导致对源图像块的大量非连续像素地址访问的问题。该问题是图像旋转本身所特有的,如果得不到很好解决,Ping-Pong双缓冲数据传输机制就无法发挥作用,旋转算法的实际DSP执行效率也就得不到真正的提高。因此,实现满足调入/调出图像块关系的数据调度就成为实现高效图像旋转的关键。
3.2 旋转算法的DSP数据调度策略
本文提出的基于视口图像块覆盖的源图像数据分块及其调度策略的思想是实现源图像及视口图像按块处理,源图像块的范围覆盖视口图像块,且易于在源图像块内进行像素数据访问寻址,使源图像块内像素地址变化具有连续的特征,以充分发挥出DSP EDMA的效率,并满足Ping-Pong数据流程的规律性。旋转算法DSP数据调度策略示意图分别如图4和图5所示,其要点如下(以视口顺时针旋转为例):
(1)视口输出图像分块
如图4(a)所示,将视口图像分成矩形块,作为每次旋转运算的基本单位,图像块之间依次排列。
(2)源图像块的取法
如图4(b)所示,每个源图像块对应一个视口图像块,源图像块的尺寸取为视口图像块尺寸的4倍(如视口块尺寸为20×20像素,则源图像块就取为40×40像素),且源图像块的上边框中点与相应的视口图像块旋转后的左上角顶点对应,这样可保证顺时针旋转角度在0°~90°之间的任意情况下,源图像块始终覆盖其对应的旋转后的视口图像块。


(3)两图像块顶点地址对应关系
设第N个源图像块为fN(x,y),旋转后的视口图像块为f′N(x,y),则源图像块的顶点局部坐标地址值与旋转后视口图像块的顶点局部坐标地址值之间的对应关系为:

其中width指源图像块的宽度。
视口逆时针旋转的情况与此类似(如图5所示)。区别有以下两点:
①源图像块的左边框中点与相应的视口图像块旋转后的左上角顶点对应;
②源图像块的顶点局部坐标地址值与视口图像块的顶点局部坐标地址值之间的对应关系式应为:

其中height指源图像块的高度。
(4)图像块的调度
由式(3)或式(4)计算出将要从源图像中取出的对应规则图像块的左上角顶点坐标(即源图像块的起始地址),然后用EDMA的二维数据传输将其调入片内L2 SRAM中。可以看出,源图像块不再随旋转角度的变化而倾斜,其内部像素的排列存在固定规律,像素地址具有连续变化的特征,故可使Ping-Pong双缓冲数据传输机制下的EDMA二维数据传输顺利进行。
这种基于视口图像块覆盖的旋转算法DSP数据调度策略有效地解决了图像旋转中大量非连续像素地址访问的问题,体现了空间换时间的思想,通过充分利用EDMA的高效数据传输,保证了整个旋转处理的高速运算节奏。
4 实验及其结果
实验采用自行研制的高分辨率图像处理平台,以TMS320DM642芯片为主处理芯片,时钟为600MHz,片外为64MB SDRAM。实验中源图像通过调试JTAG口输入,旋转后的视口图像结果从VPORT口经D/A转换后,以VGA信号输出。实验分别实现两种尺寸(400×400像素和1024×768像素)的视口图像旋转,相应的源图像数据分别为1024×768像素和1920×1920像素的BMP格式的数字地图图像,采用0.005弧度旋转角度递增间隔,对分别采用式(1)的传统像素逐点矩阵相乘方法、基于图像线性存储结构方法以及基于本文数据调度策略的结构优化的线性存储结构方法三种实现方式进行对比,分别统计其平均每帧运行时间并转换成帧率,其结果如表1所示。
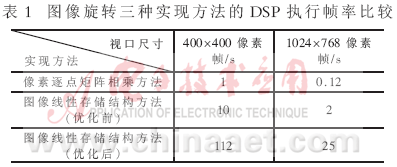
从实验结果可以看出,基于图像线性存储结构的旋转算法比传统的逐点相乘法的确在运算量上有了大幅度削减,因而有效地提高了旋转速度,但其仍然满足不了实际大图像旋转的实时性要求。通过采用本文提出的数据调度策略对算法结构及数据调度进行优化后,算法的DSP执行效率得到了显著提高,可以满足对DSP大图像旋转的实时性要求。
本文结合TMS320DM642的性能结构特点,针对图像旋转算法在DSP平台上具体实现过程中存在的严重影响DSP CPU效率发挥的大量非连续图像像素地址访问的问题,提出了切实有效的基于视口图像块覆盖的DSP数据调度策略;对算法的结构流程、数据调度等进行了优化调整,并在此基础上,在TI TMS320DM642 DSP上实现了一种实时高质量大图像旋转方案。实验表明,本文提出的适用于图像旋转算法的DSP数据调度策略,保证了DSP大图像旋转的实时性,达到了实用性要求。
参考文献
[1] 张克黛,李智.图像旋转的快速实现方法研究[J].指挥技术学院学报,1999,(10)2:29-32.
[2] 胡慧之,纪太成.DSP视频处理系统的数据传输优化设计[J].泰州职业技术学院学报,2006,(6)3:28-30.
[3] DANIELSSON P E.High-Accuracy Rotation of Images[J].Graphical Models and Image Processing,1992,54(4):340-344.
[4] 曾庆如,毕笃彦,王洪迅.TMS320C64x EDMA的图像数据传输优化[J].电视技术,2005,(278):66-72.
[5] 李方慧,王飞,何佩琨.TMS320C6000系列DSPs原理与应用(第2版)[M].北京:电子工业出版社,2003.